K210开发板实战指南:从基础到项目应用
本文详细介绍了K210开发板的各类应用,涵盖串口通信、I/O控制、PWM、舵机驱动、中断处理及图像采集与检测等核心技术。同时分享了实用的小技巧和完整项目案例,如人脸识别、温度检测和语音播报,助力开发者快速上手并实现创新项目。
K210开发实战:从环境配置到数字人系统部署与扩展
在边缘计算与本地化AI应用日益普及的今天,如何在资源受限的嵌入式设备上运行复杂的数字人生成系统?这不仅是技术挑战,更是产品落地的关键一步。K210作为嘉楠科技推出的RISC-V架构AI芯片,凭借其低功耗、高集成度和良好的NPU支持,成为许多开发者构建轻量级智能系统的首选平台。本文将以HeyGem数字人视频生成系统为例,带你完整走通从开发环境搭建、系统部署到功能优化乃至二次开发的全流程。
开发环境准备
要让HeyGem系统跑起来,首先得把“地基”打好。无论是用于服务器端调试还是K210边缘端部署,基础软硬件的准备都至关重要。
硬件选型建议
K210本身是一颗裸片,实际使用中我们通常选择集成度更高的开发板。Sipeed的Maix系列(如Maix Bit、Maixduino)是目前社区生态最完善的方案之一。它们不仅集成了摄像头、麦克风和LCD屏幕,还提供了丰富的GPIO接口,非常适合做音视频相关的AI项目。
核心硬件清单:
- K210开发板 ×1:推荐带WIFI模块的型号以增强联网能力
- Type-C数据线 ×1:用于供电和固件烧录
- SD卡(≥8GB)×1:可选,用于存放模型或输出文件,提升存储灵活性
⚠️ 注意事项:如果你只是在PC或服务器上测试HeyGem系统功能,则无需K210硬件;但若计划进行边缘端部署或性能调优,强烈建议配备真实设备进行验证。
软件依赖安装
系统运行依赖Python环境及相关库支持。以下是在Ubuntu/Debian系统下的标准安装流程:
# 更新包管理器并安装基础工具
sudo apt update
sudo apt install python3 python3-pip git ffmpeg -y
# 安装PyTorch(CPU版本)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
# 安装其他必要依赖
pip3 install gradio numpy opencv-python flask
如果主机支持CUDA且希望启用GPU加速,请根据你的显卡驱动版本选择对应的PyTorch安装命令。例如对于CUDA 11.8:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
安装完成后可通过以下命令简单验证:
python3 -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
看到True表示GPU已就绪。
部署HeyGem数字人系统
一切准备就绪后,就可以开始部署这个能“开口说话”的数字人引擎了。
获取项目代码
通过Git克隆官方仓库:
git clone https://github.com/kege/heygem-video-generator.git
cd heygem-video-generator
进入目录后,你会看到一个结构清晰的工程布局:
.
├── start_app.sh # 启动脚本
├── app.py # 主Web应用入口
├── core/
│ ├── audio_processor.py # 提取音频特征
│ ├── video_renderer.py # 渲染合成画面
│ └── lip_sync_model.py # 驱动口型同步的核心模型
├── outputs/ # 生成视频默认保存路径
├── models/ # 模型文件目录(需自行下载)
└── webui/ # 前端资源文件
🔐 安全提醒:
models/中的.bin或.onnx模型可能涉及版权保护,请确保合法获取,并仅限个人学习使用,禁止商业分发。
启动脚本解析
项目提供了一个简洁的启动脚本 start_app.sh,内容如下:
#!/bin/bash
export FLASK_APP=app.py
nohup python3 app.py > /root/workspace/运行实时日志.log 2>&1 &
echo "HeyGem 系统已在后台启动"
echo "访问地址: http://localhost:7860"
这段脚本做了三件事:
1. 设置Flask主程序为app.py
2. 使用nohup将服务挂起运行,即使终端关闭也不会中断
3. 将所有输出重定向至指定日志文件,便于后续排查问题
启动后可通过以下命令查看运行状态:
tail -f /root/workspace/运行实时日志.log
你会发现日志中不断刷新着模型加载、音频采样率检测等信息——这意味着系统正在正常工作。
WebUI操作界面介绍
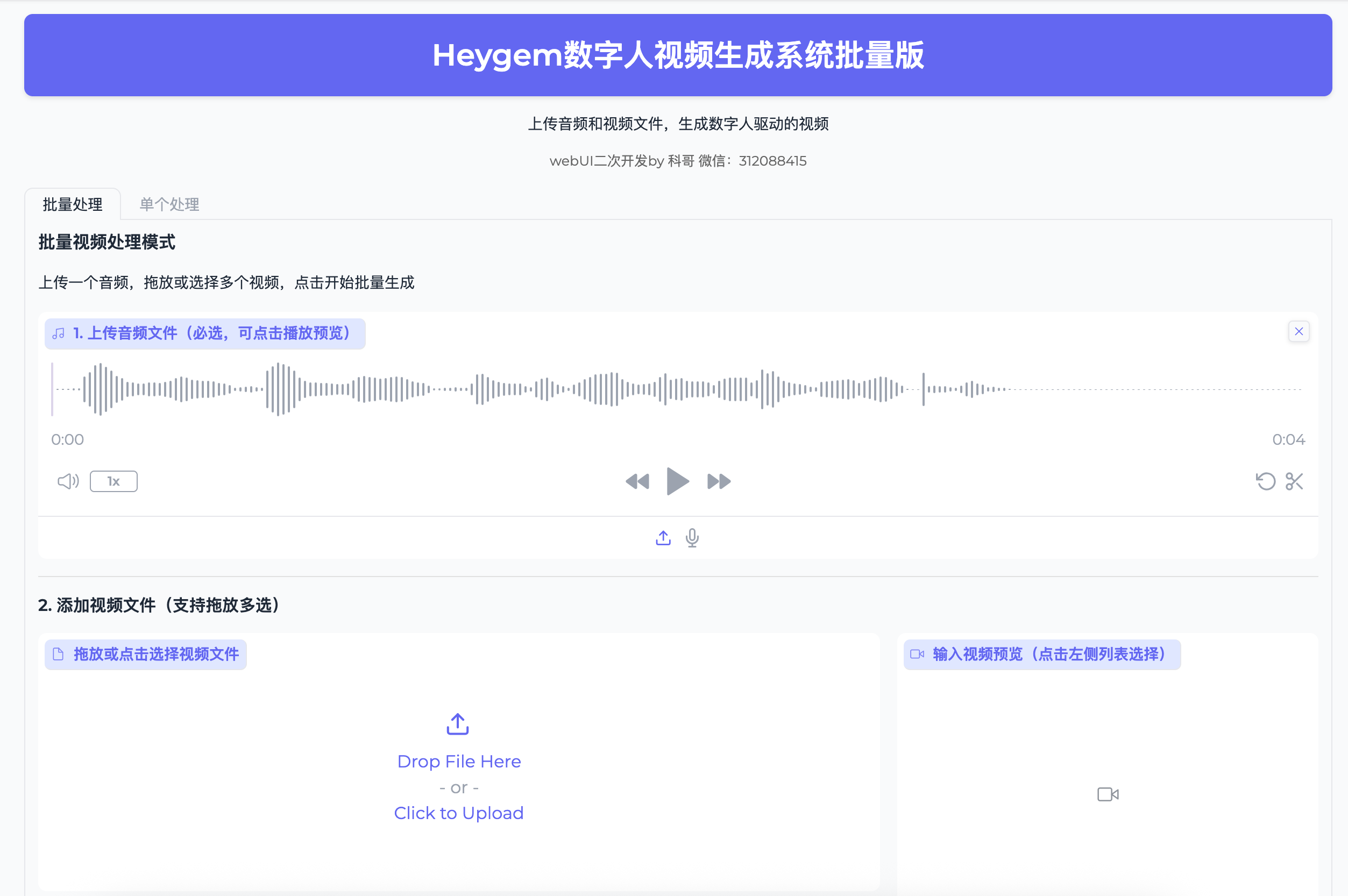
HeyGem采用Gradio构建前端界面,无需编写代码即可完成复杂任务。界面分为两个主要模式:批量处理与单个处理,满足不同场景需求。
功能模式深度解析
批量处理模式:高效产出系列内容
当你需要制作课程讲解、产品宣传视频合集时,批量模式就是你的生产力利器。
使用流程详解
第一步:上传音频素材
点击“上传音频文件”,支持格式包括 .wav, .mp3, .m4a, .aac, .flac, .ogg。上传后可直接预览音质,确认无杂音、断点等问题。
第二步:添加多个视频模板
支持拖拽或多选上传多个视频(.mp4, .avi, .mov, .mkv, .webm, .flv),系统会自动加入左侧队列列表。
第三步:管理视频队列
- 预览:点击任一列表项可在右侧窗口播放
- 删除:勾选后点击“删除选中”
- 清空:一键清除全部任务
第四步:开始批量生成
点击“开始批量生成”,系统进入处理状态,显示当前进度条、已完成数量及实时状态提示。
第五步:结果查看与导出
生成完成后,所有视频出现在“生成结果历史”面板中:
- 点击缩略图在线预览
- 单击下载图标获取单个文件
- 使用“📦 一键打包下载”生成ZIP压缩包,方便整体迁移
第六步:历史记录维护
支持分页浏览和多选删除,避免长时间运行导致磁盘占用过高。
📌 实践建议:建议每次批量任务控制在10个以内,避免内存溢出。若需处理大量任务,可结合外部脚本分批提交。
单个处理模式:快速验证与调试
适合初次使用者快速上手,也常用于算法调参或模型替换后的即时反馈。
操作步骤
- 左侧上传音频,右侧上传视频,两者均可预览
- 点击“开始生成”按钮,等待处理完成
- 结果直接展示在下方“生成结果”区域,支持播放与下载
相比批量模式,这种方式响应更快,更适合做精细调整。
性能优化与实用技巧
别小看这些细节,正确的输入准备和参数设置往往能让效率翻倍。
文件准备建议
音频方面
- 使用清晰的人声录音,优先选用专业麦克风
- 录制环境尽量安静,避免空调、风扇等背景噪音
- 推荐格式:
.wav(无损)、.mp3(兼容性好)
视频方面
- 人物正面出镜,脸部占据画面主要区域
- 光线均匀,避免逆光或强阴影影响识别
- 分辨率建议720p或1080p,过高的4K反而增加处理负担
- 编码格式推荐H.264 + AAC音频,通用性强
✅ 理想输入示例:
- 音频:安静房间内录制的标准普通话语音
- 视频:固定机位拍摄的主持人正脸特写,背景简洁
性能调优策略
| 优化方向 | 具体建议 |
|---|---|
| 批量合并处理 | 多视频统一处理比逐个运行节省约30%时间(减少重复模型加载) |
| 控制视频长度 | 单个视频不超过5分钟,防止内存爆满 |
| 并发控制 | 系统自动排队执行,避免资源竞争导致崩溃 |
| 模型缓存复用 | 首次运行较慢,后续任务共享已加载模型,速度显著提升 |
💡 GPU加速提示:若服务器配有NVIDIA GPU,系统将自动检测并启用CUDA进行推理加速,合成速度可提升3~5倍。可通过日志确认是否启用成功。
常见问题解答
Q:为什么处理速度特别慢?
A:首先检查是否启用了GPU。其次关注视频时长和分辨率,过长或过高都会显著拉长处理时间。建议先用短片段测试流程通畅性。
Q:支持哪些分辨率?
A:理论上支持480p至4K,但推荐使用720p~1080p,在画质与效率之间取得最佳平衡。
Q:生成的视频保存在哪里?
A:默认存储于项目根目录下的 outputs/ 文件夹中,命名规则为时间戳+任务类型,也可通过Web UI直接下载。
Q:能否同时运行多个任务?
A:不可以。系统采用FIFO先进先出队列机制,按顺序逐一处理,防止并发引发资源冲突或内存泄漏。
Q:如何查看运行日志?
A:使用以下命令追踪实时日志:
tail -f /root/workspace/运行实时日志.log
日志中包含模型加载耗时、帧率统计、异常堆栈等关键信息,是排错的第一手资料。
高级应用与二次开发指南
当基本功能满足不了你的创意时,是时候深入底层,定制专属能力了。
日志监控:掌握系统脉搏
系统日志不仅仅是错误记录,更是性能分析的重要依据。除了常规查看方式外,还可以结合grep过滤关键信息:
# 查找所有错误信息
grep -i error /root/workspace/运行实时日志.log
# 统计每日任务数
grep "Task started" /root/workspace/运行实时日志.log | wc -l
你甚至可以将日志接入ELK栈实现可视化监控,适用于长期运行的服务场景。
接口扩展思路
目前系统基于Gradio构建,但其接口设计具备良好延展性。你可以轻松添加新功能模块。
例如,新增一个支持水印叠加的功能:
import gradio as gr
from PIL import Image, ImageDraw, ImageFont
def add_watermark(video_path, text="Hello HeyGem"):
# 此处调用OpenCV逐帧处理
output_path = video_path.replace(".mp4", "_wm.mp4")
# 添加文字水印逻辑...
return output_path
with gr.Blocks() as demo:
gr.Markdown("## 添加水印功能")
with gr.Row():
video_in = gr.Video(label="输入视频")
text_in = gr.Textbox(value="Powered by K210", label="水印文字")
btn = gr.Button("添加水印")
video_out = gr.Video(label="输出视频")
btn.click(fn=add_watermark, inputs=[video_in, text_in], outputs=video_out)
demo.launch(server_name="0.0.0.0", server_port=8080)
🛠️ 可拓展方向还包括:
- 字幕自动叠加(结合ASR识别结果)
- 导出GIF动图用于社交媒体传播
- 封装REST API对外提供服务
- 支持定时任务自动生成日报类视频
自定义模型集成
HeyGem的核心在于口型同步模型(Lip Sync Model)。如果你想用自己的训练成果替代原有模型,完全可行。
替换步骤
- 将训练好的模型(
.onnx或.pth)放入models/目录 - 修改
core/lip_sync_model.py中的加载路径 - 确保输入输出张量尺寸匹配
import onnxruntime as ort
# 加载自定义ONNX模型
session = ort.InferenceSession("models/custom_lip_sync.onnx")
def predict_lip_movement(mel_spectrogram):
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
pred = session.run([output_name], {input_name: mel_spectrogram})[0]
return pred
⚠️ 关键注意事项:
- 输入必须为 Mel-Spectrogram(80维 × T帧)
- 输出应为面部关键点坐标序列(N×2格式)
- 预处理流程需保持一致,否则会导致口型错乱
- 建议先在PC端验证模型正确性,再部署到边缘设备
此外,K210对ONNX模型的支持较为友好,可通过nncase工具链进一步转换为.kmodel格式,实现更高效的本地推理。
这种高度集成化的开发模式,正推动着数字人技术从云端走向终端。借助像K210这样的边缘AI芯片,我们不仅能降低延迟、保障隐私,还能在离线环境下稳定运行复杂AI任务。未来,随着模型压缩技术和硬件算力的持续进步,更多原本只能在服务器上运行的AI系统,都将有机会走进千家万户的智能设备之中。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)