Triton&九齿系列(五)《天数智芯 Triton 实战》
天数智芯通过适配Triton框架实现了国产GPU的高效AI计算,主要优势包括:1)基于LLVM生态的无缝兼容;2)GPGPU架构的高度契合;3)支持Triton Kernels零改写复用。适配工作聚焦编译器层优化,在FlashAttention算子中实现了Block Tiling、MMA指令优化和延时归约等技术,使V2版本性能显著提升。该方案支持开发者直接迁移现有Triton代码,为国产AI芯片生
目录
本文从 CUDA 兼容到性能优化,天数智芯如何让 Triton 在国产 GPU 上高效运行。
天数智芯与 Triton 的适配优势
1. LLVM生态兼容
-
• 天数智芯的自研软件栈编译器基于 LLVM 开发,而 Triton 本身也依赖 MLIR 和LLVM等基础设施。这意味着 Triton 的工具链优化流程能与天数智芯编译器无缝对接,无需额外翻译。
2. GPGPU 架构契合
-
• 天数智芯 GPU 采用 GPGPU 架构,与 Triton 最初支持的 NVIDIA GPU、AMD GPU 架构相似,内存模型相似、计算模型一致,因此 Triton 中针对 GPGPU 的中间表示优化手段可直接复用
3. Triton Kernels 零改写复用
-
• 这是对开发者最友好的优势,无需修改代码,Triton 经验可直接迁移。如需进一步提升性能,可针对特定 kernel 进行优化
天数智芯 Triton 适配
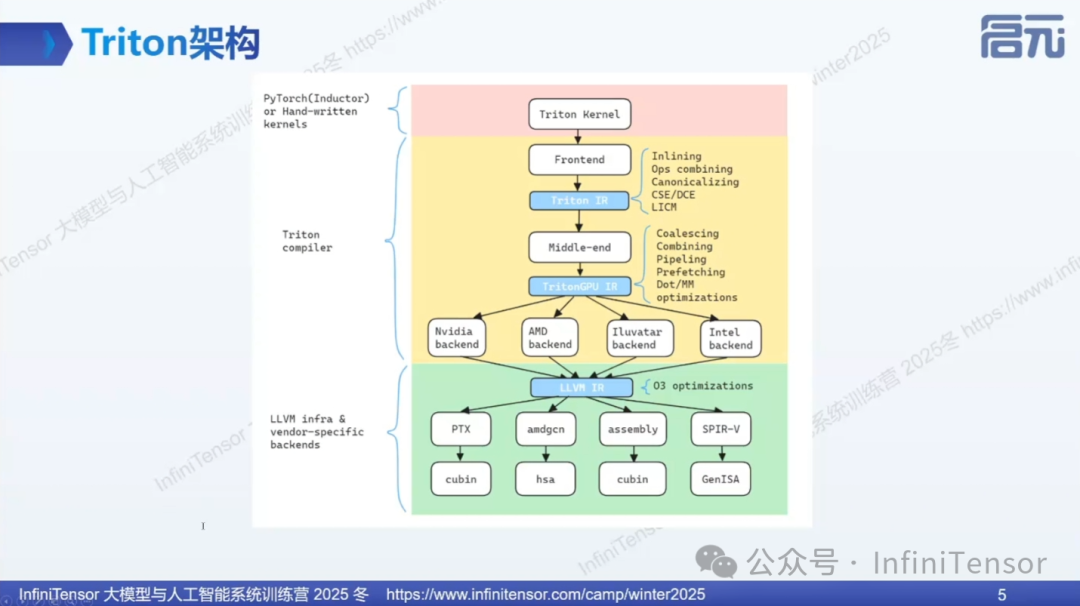
1. Triton 架构分层
-
• Kernel 层:用户编写或自动生成的算子
-
• 编译器层:对 kernel 进行基础优化和GPU专用优化
-
• LLVM 与硬件后端层:将 Triton GPU IR 转换为硬件指令
2. 适配工作的三个层面

天数智芯 Flash Attention 算子优化
-
• V0版本:官方实现支持
-
• V1版本:head_dim 切分优化
-
• V2版本:转置视图优化
Block Tiling

-
• Grid划分:对 sequence length 维度按block m 切分
-
• 任务分配:不同线程块并行处理不同的batch、head 和 sequence length 分段
V1版本 Block Tiling

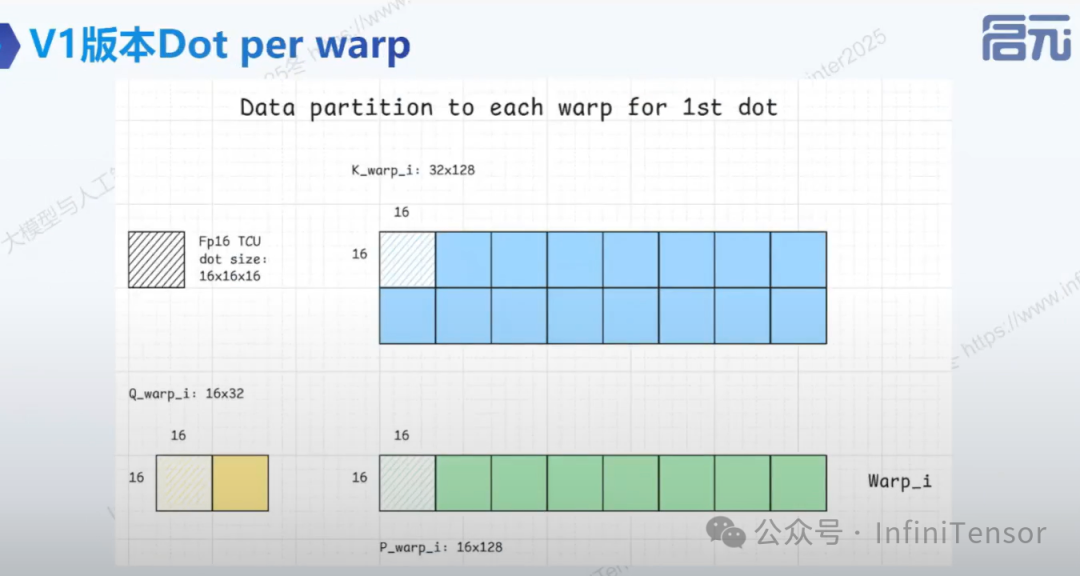
1. V1版本 warps per tile

-
• Warp 垂直排列:每个 warp 负责一个 16×128 的横条
-
• 优势:
-
• 减少跨 Warp 数据交换
-
• 避免数据排布转换
-
• 提升计算效率
-
2. MMA 指令

-
• 线程负载计算:
-
• 矩阵 A 总元素量: 个 FP16 元素。
-
• Warp 分配:。即每个线程寄存器需存储 8 个 FP16 元素。
-
-
• 寄存器片段布局 (Fragment Layout):
-右侧图表展示了矩阵 A 在 Warp 内的物理映射。 -
• 非连续分布:以 T0 (Thread 0) 为例(红框标记),它持有的 8 个元素 () 并非在矩阵中连续排列,而是分散映射。例如:
-
• 位于 Row 0, Col 0-1。
-
• 位于 Row 0, Col 8-9。
-
• 位于 Row 8, Col 0-1。
-

-
• 线程负载计算:
-
• 矩阵 c 总元素量: 个 FP16 元素。
-
• Warp 分配:。即每个线程寄存器需存储 4 个 FP16 元素。
-
-
• 寄存器片段布局 (Fragment Layout):
-
• 右侧图表展示了这 4 个元素在物理空间中的映射逻辑,以 T0 (Thread 0) 为例(红框标记)
-
• 寄存器分配:包含两个 .f16x2 寄存器,分别存储 和 。
-
• 空间映射 (Layout)::映射在矩阵的 Row 0, Col 0 位置。:映射在矩阵的 Row 8, Col 0 位置。
-
• 布局特点:数据并非连续排列,而是存在 8 行的跨度 (Stride)。T0 虽然只负责第 0 列的数据,但被拆分到了矩阵的上半部分(Row 0)和下半部分(Row 8)。这种特定的 Swizzling 布局是为了配合 Tensor Core 在 K 维度上的高效数据读取与累加。
-

-
• 线程负载计算:
-
• 矩阵 B 总元素量: 个 FP32 元素。
-
• Warp 分配:。即每个线程寄存器需存储 4 个 FP32 元素。
-
-
• 物理映射:
-
• 空间分布:与矩阵 B 的布局高度一致。Thread 0 (红框) 持有的 位于 Row 0, Col 0-1,而 位于 Row 8, Col 0-1。
-
• 意义:这种布局确保了计算结果可以直接作为下一次 MMA 运算的输入(Accumulator),或者通过简单的 Shuffle 操作存回 Shared Memory/Global Memory。
-

3. 天数 FP16 TCU 指令

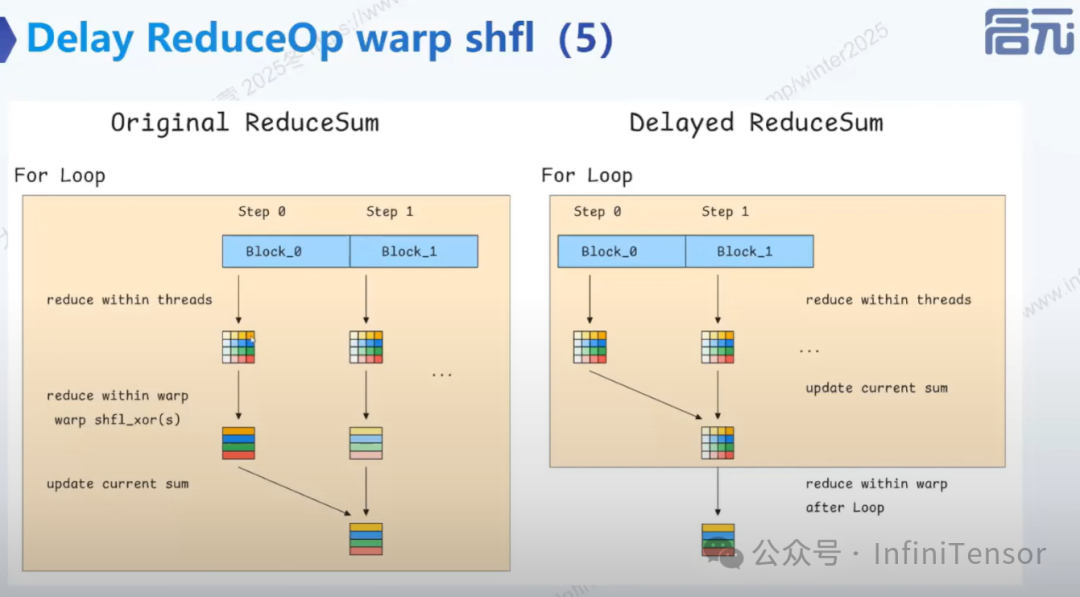
4. 延时归约优化
-
• 原流程:沿 k 遍历,每步分线程内归约、warp 内线程归约,与前步结果求和更新部分和,每步都做归约操作
-
• 延时归约:去掉 warp 内归约,放到循环最后,中间计算结果更新为部分累加和(Partial Sum),循环结束后不同线程结果求和得最终正确结果,省去每步开销
V2 版本 Block Tiling

-
• V2版本更快的原因
-
• Reduce 方向改变:减少中间指令数量
-
• 避免 MMA 结果在不同 Operand 表示之间的额外转换,降低数据重排与指令开销
-
总结
天数智芯通过深度适配Triton,为国产 GPU提供了高效的算子开发解决方案,使得开发者能够轻松将现有 Triton 代码迁移到天数智芯 GPU 上。随着更多算子的适配和优化,天数智芯 GPU 的生态将更加丰富,为国产 AI 芯片的发展提供强大支持。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)