谷歌TPU能否挑战英伟达GPU的垄断地位?从架构到供应链的全面拆解
从架构、软件生态、供应链、成本四个维度,拆解谷歌TPU和英伟达GPU的核心差异,分析TPU能否打破GPU的垄断地位。
最近几年,AI芯片市场出了一些有意思的变化:苹果的Apple Intelligence全部用TPU训练,Anthropic拿下100万颗TPU训练下一代Claude,Meta也签下数十亿美元协议租TPU跑LLaMA。越来越多的顶级模型公司,开始把谷歌TPU当作英伟达的替代方案。
这篇文章从硬件架构、软件生态、供应链、成本等多个维度,拆解一下TPU和GPU的核心差异,聊聊我对这场AI芯片之争的一些看法。
一、架构差异:并行大厨 vs 流水线
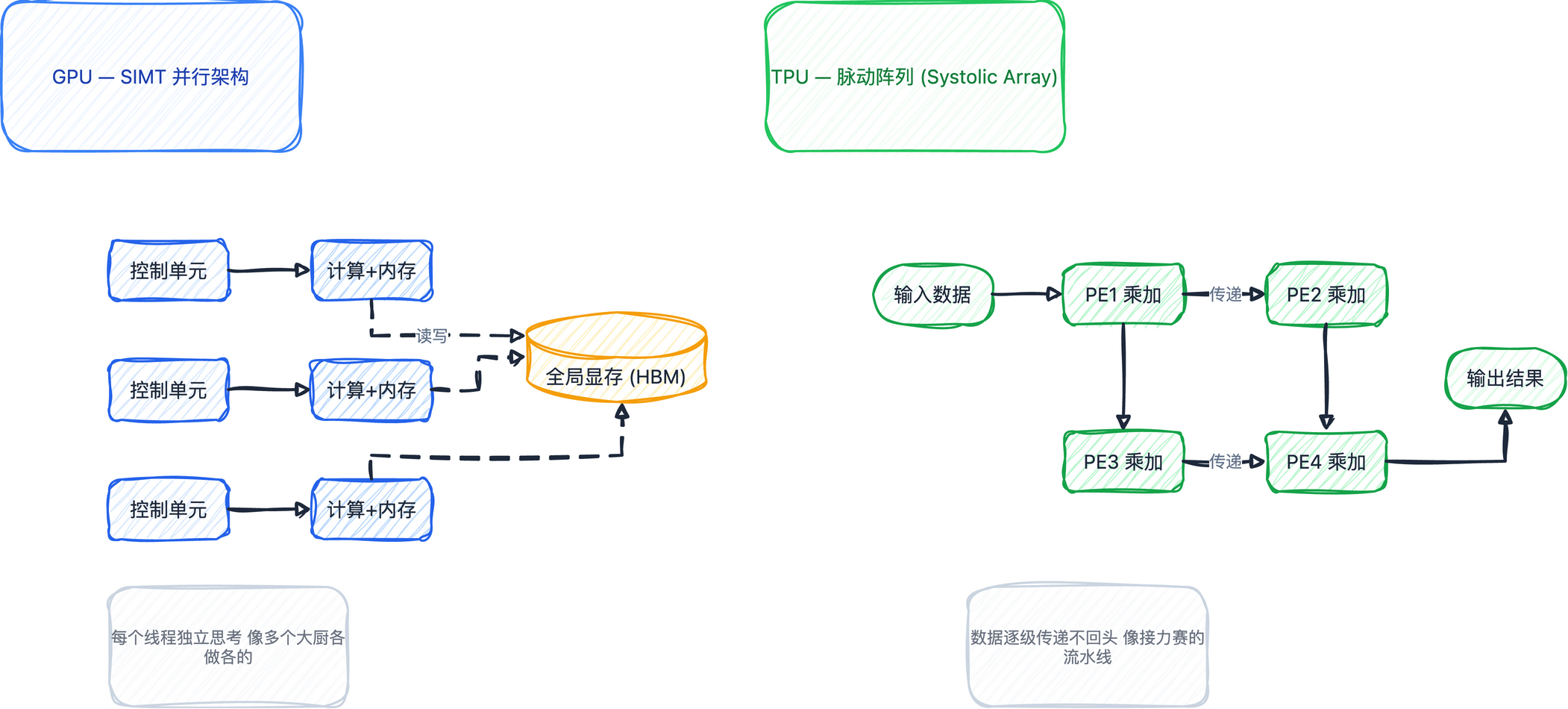
GPU:SIMT架构
GPU最早是做游戏显卡的,用的是SIMT(Single Instruction Multiple Threading)架构——多线程单一指令。
打个比方,就像一个厨房里安排了几百个大厨,每个人都有独立的思考能力,独立从冰箱拿食材、做菜、上菜,并行能力非常强。
TPU:脉动阵列架构
TPU的思路完全不同。机器学习算法的核心就是矩阵计算,TPU就是针对矩阵计算专门做的定制加速器。
还是用厨房的比方:TPU不需要那么多大厨,而是把每个人安排在流水线的具体步骤上。第一个人从冰箱取食材,做完直接传给第二个人加工,再传给第三个人。每一步像心脏泵血一样,中间没有多余的调度和调控,保证每个计算单元的利用率更高。
一句话总结:GPU是并行作战,TPU是接力赛。
二、训练效率:谁更省钱?
我的判断是:针对自家定制的大模型,TPU的TCO(总拥有成本)更有优势。
原因有两点:
1. 更高的利用率
GPU的SIMT架构有个缺陷——因为每个线程独立计算,经常要等数据搬运过来,中间会有空闲期(idle period),导致矩阵计算利用率上不去。
TPU的做法是软硬件协同:硬件变"笨"一点,变成机械式劳作;所有复杂的调度、算子融合、内存管理全交给软件(XLA编译器)来处理。这样能保证满功率运行,不用等数据搬运。
2. 系统级设计 vs 单卡性能
GPU很长一段时间走的是单卡性能路线,每张卡性能拉满。而TPU从一开始就是做TPU Pod——几千张卡组成的协同训练集群。芯片之间用ICI(Inter-Chip Interconnect)直接通信,通过3D Torus拓扑网络,让几千张芯片在用户感知中像一张卡在训练。
到了Ironwood(V7),TPU在物理参数上已经非常接近GB200,训练效率和GPU旗鼓相当。
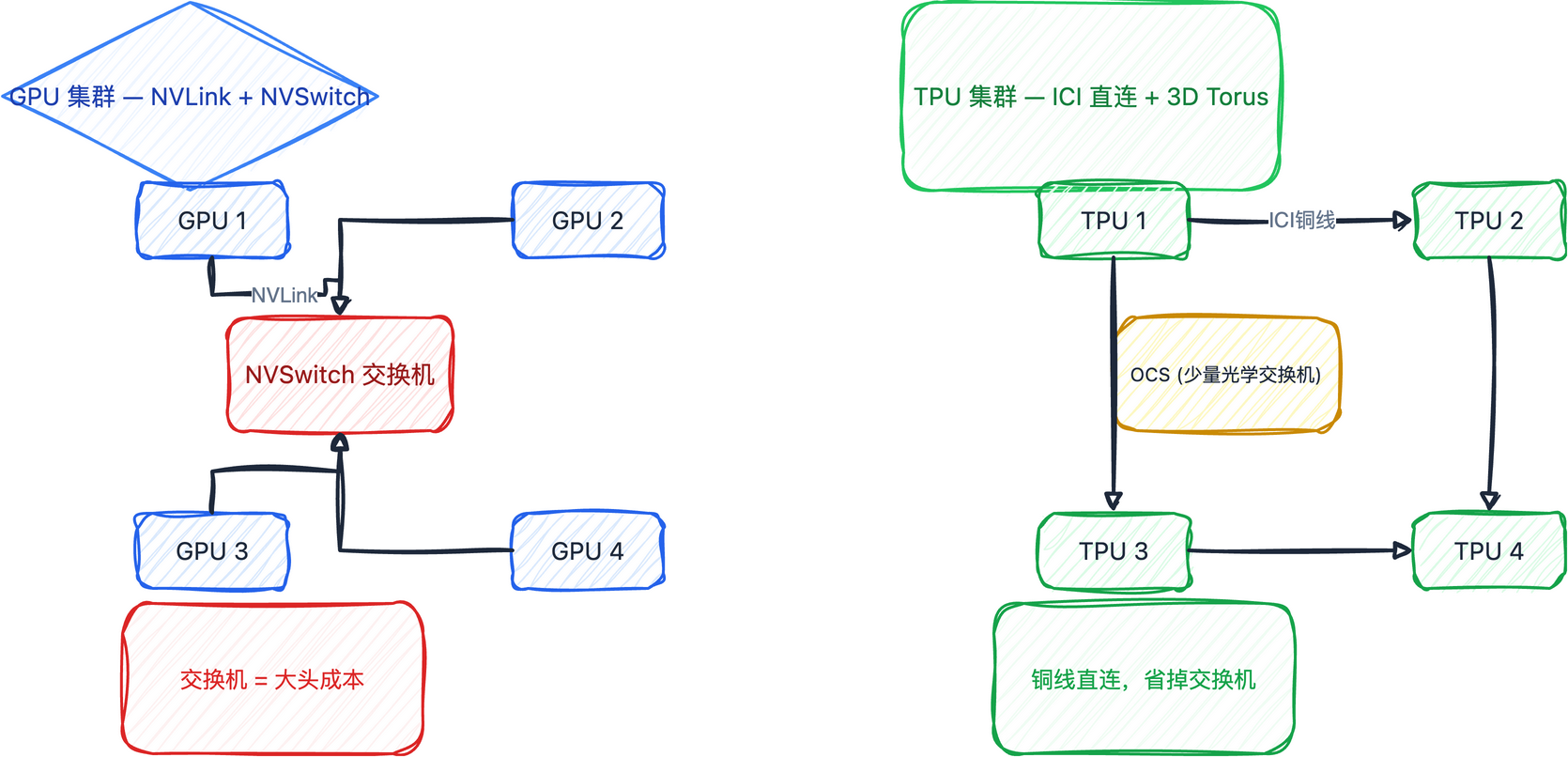
三、数据中心成本:拉开差距的地方
这是一个容易被忽视但非常关键的点。
GPU集群用NVLink和NVSwitch做芯片间通信,这套交换机方案本身就很烧钱,算是一种基础设施税。需要找各种厂商采购交换机,部署到数据中心。
TPU集群用的是不一样的拓扑架构:芯片与芯片之间直接用铜线通信,不需要交换机;只在部分节点上用少量光学交换机(OCS)。实现同样的通信效果,成本低了不少。
所以在建数据中心这一环,成本已经拉开了。
四、XLA:TPU的秘密武器,也是最大的门槛
XLA是什么
XLA是TPU的编译器,对标英伟达的CUDA生态。上层接PyTorch、JAX、TensorFlow,中间做翻译+优化,最终生成TPU的底层指令。
XLA是一个静态编译器,当workload已知时,它可以在整个TPU Pod的系统层面做全局优化:
- 算子融合:把多个计算合并到一个计算单元,减少中间结果的反复存取
- 内存管理:根据硬件特性优化数据读取方式
- 通信调度:在集群层面安排芯片间的数据传输
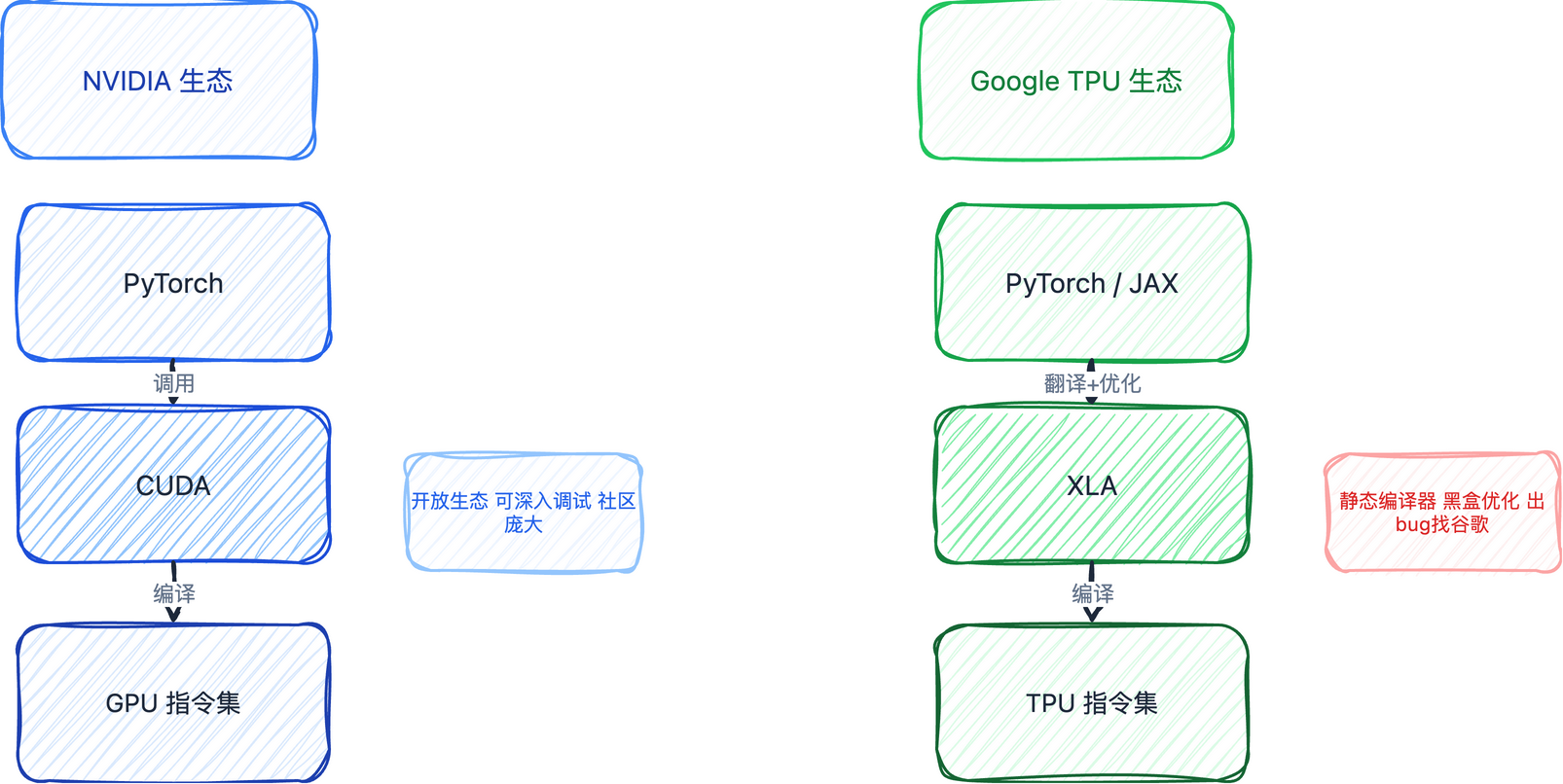
黑盒问题
XLA的问题在于——它是个黑盒。优化效果很好,但出了问题很难debug。它把很多算子做了融合,内存做了重新管理,形成的是一个图(graph),不是单个计算。debug需要对底层硬件有深入了解。
如果XLA出bug,外部开发者很难独立修复,基本要靠谷歌工程师来处理。 这和CUDA的开放生态形成了鲜明对比。
为什么Anthropic能用好TPU
Anthropic的很多工程师最早在谷歌,熟悉XLA和JAX这套体系。加上Anthropic和谷歌本身有深度投资关系,属于"内循环"。所以Anthropic是少数能把TPU性能榨干的外部公司。
据公开信息,直接购买TPU机架(而非通过谷歌云)的外部公司,目前只有Anthropic。 苹果、Midjourney、Meta都还是在谷歌云上用。
五、通过谷歌云用TPU,性能要打几折?
这个问题的答案可能让不少人吃惊。
如果软硬件结合得好,TPU能接近满状态跑到peak FLOPS和peak memory bandwidth。但如果通过谷歌云来跑,利用率可能只有50%-60%——你付的是100%的钱,但只用到一半多的性能。
这也是为什么有能力的公司(如Anthropic)宁愿直接买机架,自己做深度调优。
六、供应链:TPU的三大瓶颈
1. HBM供应
HBM(高带宽内存)被三家公司垄断:SK海力士、三星、美光。英伟达一直是HBM最大客户,TPU长期是secondary customer,拿不到最好的供货和最大的订单。
随着AI从compute-bound转向memory-bound,HBM的重要性越来越高。尤其是attention kernel,核心就是怎么更快地从内存搬运数据。未来HBM的好坏,可能直接决定训练效率的上限。
2. CoWoS封装
现在的AI芯片都是chiplet设计——HBM内存芯片和计算芯片是两块独立芯片,通过2.5D封装集成在一起。这个封装只有台积电(TSMC)能做,产能按订单量分配,英伟达量大优先。
3. 良率问题
TPU主打芯片间通信,对一致性要求极高。一旦某颗芯片性能不达标,整个系统效率就下降。不像GPU可以降级卖阉割版(H100→A100),TPU的定制芯片一旦良率不行,基本就报废了。
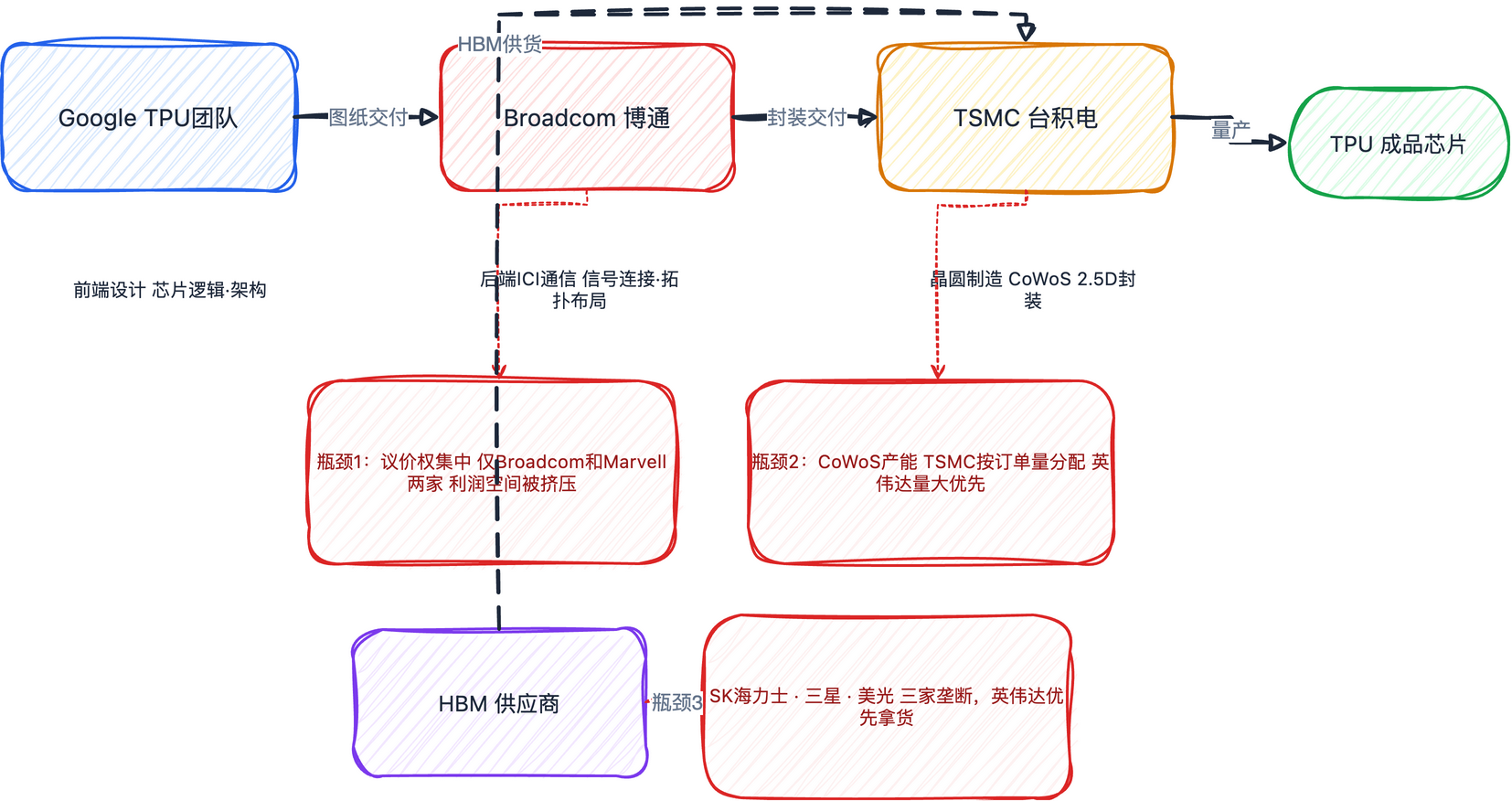
七、Broadcom:TPU背后的关键供应商
TPU团队负责设计芯片前端(画图纸),Broadcom负责把芯片与芯片在物理上连接起来——做ICI通信、后端布局、信号传输,最后交付给台积电量产。
这是一个技术壁垒极高的环节。TPU的通信涉及混合信号(模拟+数字电路),对经验要求很高。目前市场上能做这件事的只有Broadcom和Marvell两家。
但这也带来了风险:Broadcom的议价权越来越大,TPU中间能赚的利润越来越少。 如果没有backup方案,成本很难控制。
八、TPU的进化史
| 阶段 | 版本 | 时间 | 核心变化 |
|---|---|---|---|
| 起步期 | V1 | ~2015 | 纯推理芯片,针对内部CNN模型加速,替代CPU做inference |
| 奠基期 | V2-V3 | ~2016-2018 | 加入训练能力,支撑AlphaGo、早期Transformer训练,建立TPU Pod拓扑网络 |
| 扩展期 | V4-V5 | ~2022-2023 | 加入Sparse Core稀疏计算单元,优化推荐/排序算法;引入OCS光学交换机解决MoE通信瓶颈 |
| 大模型期 | V6 | ~2024 | 全面转向Transformer优化,首次分离训练/推理两个版本 |
| 成熟期 | V7(Ironwood) | 2025 | 物理参数接近GB200,memory bandwidth大幅提升,系统稳定性达到生产级 |
TPU诞生的故事
2013年左右,Jeff Dean在谷歌内部演示深度学习在语音识别上的突破。大家发现需要GPU而不是CPU。
当时Jonathan Ross(后来创办Groq,现在是英伟达VP)做了个内部demo,放了两页PPT:
- 第一页:好消息——GPU真的能work
- 第二页:坏消息——我们付不起这个钱
他们算了一笔账:如果所有用户给谷歌发3分钟语音,数据中心成本会翻倍,多出数百亿美元。这就是谷歌开始自研TPU的起点。
九、Groq:另一个TPU的"分支"
Groq的创始人Jonathan Ross之前是谷歌TPU compiler团队的founder级人物,带着一整套XLA的经验出来创业。
Groq本质上是一家编译器公司,不是芯片公司。 芯片设计得比TPU还简单,核心在于compiler能精确控制每个cycle的计算调度。
Groq踩准了三波红利:
1. Inference市场兴起——专注推理,不做训练
2. ASIC定制芯片——针对低延迟场景的专用加速器
3. Agent元年——智能体对延迟要求极高,正好是Groq的主场
但Groq也有局限:大参数量模型的成本很高,更适合小规模本地部署场景。
十、总结:TPU vs GPU的格局判断
TPU的优势:
- 软硬件协同下,矩阵计算利用率更高
- 系统级设计,数据中心部署成本更低
- 针对已知workload(如Transformer)的定制优化,训练和推理的TCO更优
TPU的劣势:
- XLA生态门槛高,外部开发者难以独立调优和debug
- 供应链受制于HBM、CoWoS和Broadcom
- 作为ASIC,一旦模型架构发生范式变革,适应能力不如通用GPU
- 推理场景需要大规模用户才能发挥成本优势,不适合单用户/低并发场景
我的判断:在限定条件下,TPU完全可以挑战GPU。 这些限定条件包括:大规模部署、模型相对稳定、有足够的工程能力做软硬件调优。
未来大概率是两者并存——有定制场景,也有通用场景;有大规模云端部署,也有小规模本地推理。一旦产能和供应链问题解决,对整个行业都是好事。
毕竟,垄断从来不是健康生态该有的样子。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)