Transformer:从语言序列到人工智能,AI新纪元的架构基石
在这场从狭隘AI走向通用AI的漫长征程中,Transformer已为我们搭建了一座坚实的桥梁,而桥的彼岸,将是更广阔、更智能的未来。:围绕Transformer大模型,形成了从硬件(专用AI芯片)、框架(PyTorch、TensorFlow)、训练技术(分布式并行、混合精度)到应用(提示工程、AI智能体)的完整生态。:Transformer正成为科学发现的新工具。正是这种摒弃递归、完全基于注意力的
引言:一场静默的范式转移
2017年的那个夏天,当谷歌研究团队的八位作者在论文《Attention Is All You Need》中提出Transformer架构时,他们可能未曾预料到,这个看似专门针对机器翻译优化的模型,会在五年内成为人工智能领域的“新电力”。从最初在NLP领域的局部突破,到如今重塑计算机视觉、语音识别、科学发现乃至艺术创作,Transformer已不仅仅是一种神经网络架构,更是一种全新的计算范式。
本文将以自然语言处理为起点,深入剖析Transformer如何通过其独特的自注意力机制重新定义序列建模,进而探讨这一架构如何跨越领域边界,推动人工智能向更通用、更强大的方向演进。我们不仅将回顾其技术演进,更将思考Transformer背后的设计哲学如何启发我们重新理解“智能”的本质。
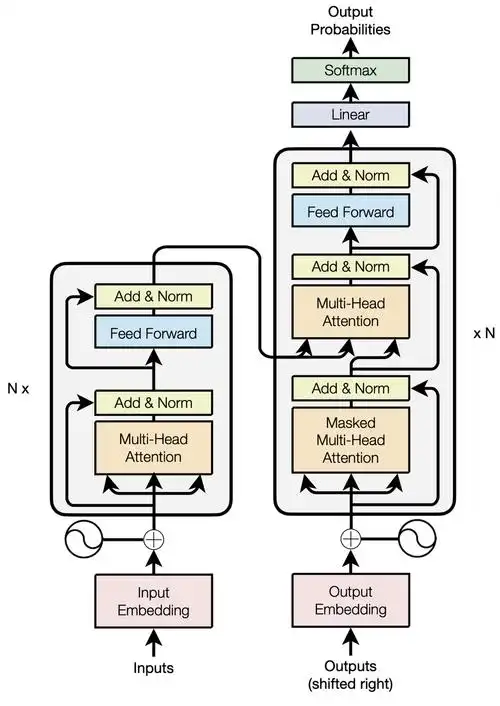
Transformer的核心突破:为什么是“注意力就是全部”?
1.1 序列建模的前Transformer时代
在Transformer诞生之前,循环神经网络(RNN)及其变体LSTM、GRU主导着序列建模。这些模型的核心思想是顺序处理:每一个时间步的隐藏状态依赖于前一个时间步的输出。这种设计带来了两个根本性限制:
-
计算效率瓶颈:顺序处理无法并行化,训练速度受到序列长度的严格制约
-
长程依赖难题:信息通过隐藏状态逐层传递,随着距离增加,早期信息容易丢失或稀释
卷积神经网络(CNN)虽能并行处理,但需要堆叠多层才能建立长距离依赖,且感受野有限。这些限制在需要全局上下文理解的任务(如文档级理解、长文本生成)中尤为突出。
1.2 自注意力:一种全新的关系建模范式
Transformer的核心创新——自注意力机制——提供了一个优雅的解决方案。其核心思想是:序列中的每个元素都应该能够直接与所有其他元素交互,而不需要通过中间状态的逐步传递。
自注意力的数学优雅性:
text
Attention(Q, K, V) = softmax(QK^T/√d_k)V
这个看似简单的公式蕴含着深刻的洞察。对于序列中的每个位置,自注意力计算它与所有位置的相关性权重,然后基于这些权重聚合全局信息。其中的缩放因子√d_k是关键技巧,防止点积值过大导致softmax梯度消失。
多头注意力:并行化的语义空间探索:
通过并行运行多个注意力“头”,模型能够在不同表示子空间中同时关注不同方面的信息。一个头可能关注语法结构,另一个关注语义一致性,第三个关注指代关系。这种设计赋予了模型同时处理多种关系类型的能力。
1.3 位置编码:在没有递归的情况下保留顺序
自注意力机制本身对序列顺序不敏感——它处理的是一个无序集合。为了注入位置信息,Transformer引入了位置编码。原始论文使用正弦和余弦函数:
text
PE(pos,2i) = sin(pos/10000^{2i/d_model})
PE(pos,2i+1) = cos(pos/10000^{2i/d_model})
这种选择并非偶然:三角函数的性质使得模型能够轻松学习到相对位置关系,且能外推到比训练时更长的序列。
1.4 残差连接与层归一化:稳定深度网络训练
Transformer通常堆叠多层(如12-24层编码器/解码器),深度网络的训练稳定性至关重要。残差连接让梯度能够直接反向传播,缓解了梯度消失问题;层归一化则稳定了激活值的分布,使训练过程更加平滑。
这些技术组件的协同作用,创造了一个能够并行处理整个序列、捕获任意距离依赖关系、且易于优化的模型架构。正是这种架构上的根本性突破,为后续的规模化扩展奠定了基础。
Transformer在NLP中的革命:从BERT到GPT
2.1 编码器革命:BERT与深度双向理解
BERT(Bidirectional Encoder Representations from Transformers) 在2018年的发布,标志着NLP从“为每个任务设计专门模型”向“预训练+微调”范式的全面转变。
BERT的双向突破:传统的语言模型(包括GPT-1)只能从左到右或从右到左单向建模,限制了上下文理解能力。BERT通过两个创新的预训练任务克服了这一限制:
-
掩码语言建模(MLM):随机遮盖输入序列中的部分token,让模型基于双向上下文预测被遮盖的内容
-
下一句预测(NSP):判断两个句子是否连续,增强模型对句间关系的理解
这种设计使BERT能够捕获词汇在完整上下文中的深层语义。在11项NLP基准测试中的全面领先,证明了深度双向预训练的有效性。
微调范式:BERT展示了同一个预训练模型可以通过简单的“任务特定头部”适配到多种下游任务。这种灵活性极大地降低了NLP应用的门槛,开启了模型共享和复用的新时代。
2.2 解码器革命:GPT与生成智能的崛起
如果说BERT代表了理解能力的突破,GPT系列则展示了生成能力的惊人潜力。
GPT-1到GPT-2:规模扩展的早期信号:GPT-1证明了仅使用解码器的Transformer在语言模型预训练中的有效性。GPT-2则通过更大规模(15亿参数)和更宽数据(800万网页)展示了零样本学习的能力——模型能够在没有任务特定微调的情况下执行翻译、摘要等任务。
GPT-3:规模引发质变:1750亿参数的GPT-3带来了真正的范式转变。其核心洞见是:当模型规模足够大、数据足够多时,模型可以通过少量示例(少样本学习)或仅凭任务描述(零样本学习)适应新任务,而无需梯度更新。
涌现能力:在GPT-3及更大的模型中,研究者观察到了“涌现能力”——某些复杂能力只在模型规模超过特定阈值时才出现。这些能力包括:
-
多步推理和思维链
-
代码生成与调试
-
跨领域概念类比
-
遵循复杂多步指令
这种涌现现象挑战了传统机器学习中“能力平滑扩展”的假设,提示我们可能存在某种“智能相变”。
2.3 预训练范式的演进
从BERT和GPT开始,预训练语言模型沿着多个方向演进:
高效架构探索:研究人员开发了多种Transformer变体以提升效率,如:
-
Longformer:结合局部和全局注意力,处理长达数千token的文档
-
Reformer:使用局部敏感哈希近似注意力,降低内存消耗
-
Big Bird:理论证明的稀疏注意力模式,保持表达力的同时提升效率
多语言与跨语言:mBERT、XLM-R等模型在多种语言上预训练,展示了强大的跨语言迁移能力,为低资源语言NLP提供了新路径。
指令微调与对齐:从InstructGPT开始,研究者意识到预训练后的“对齐”阶段同样关键。通过人类反馈强化学习(RLHF)等技术,模型学会了更好地理解人类意图、遵循指令、避免有害输出。
超越语言:Transformer的跨模态征服
3.1 视觉Transformer:当图像遇见序列
Vision Transformer(ViT) 在2020年的提出,挑战了计算机视觉领域长达十年的卷积网络(CNN)统治地位。
图像作为补丁序列:ViT的核心洞见是将图像分割为固定大小的补丁(如16×16像素),然后将每个补丁线性投影为向量,添加位置编码后输入标准Transformer编码器。这种简单而直接的策略,在大规模数据(如JFT-300M)预训练下,超越了当时最先进的CNN模型。
ViT的成功启示:
-
归纳偏置的权衡:CNN的局部性和平移不变性是强归纳偏置,有助于小数据学习;Transformer的全局注意力机制是弱归纳偏置,需要更多数据但潜力更大
-
统一架构的可能性:同一架构可以处理语言和视觉,为多模态融合奠定了基础
-
规模定律的普适性:NLP中观察到的规模定律(模型性能随参数和数据增加而可预测提升)似乎在视觉领域也成立
视觉Transformer的演进:随后的改进模型如Swin Transformer引入了层次化设计和移位窗口注意力,平衡了全局建模与计算效率;MAE(掩码自编码器)将BERT的掩码重建思想应用于视觉,展示了自监督学习的强大潜力。
3.2 多模态融合:统一表示学习
Transformer的真正威力在于其作为跨模态通用接口的能力。当不同模态的数据都被表示为序列时,同一套架构可以处理它们的交互。
CLIP:对齐视觉与语言:OpenAI的CLIP模型同时训练图像编码器和文本编码器,将二者映射到同一表示空间。通过对比学习,模型学会了图像与其描述之间的语义对齐,实现了强大的零样本图像分类能力。
多模态统一架构:更先进的模型如Flamingo、KOSMOS、GPT-4V直接将图像、文本、甚至音频等不同模态输入转换为统一的token序列,由单一Transformer处理。这种设计使得模型能够:
-
基于图像回答问题
-
根据文本描述生成或编辑图像
-
理解文档中的图文混合内容
-
处理视频时序信息
具身智能的桥梁:在机器人领域,Transformer被用于处理视觉观察、语言指令和动作序列的统一表示,为实现遵循自然语言指令的通用机器人控制器提供了可能。
3.3 科学发现:Transformer作为科学家的新工具
AlphaFold 2:蛋白质结构预测的革命:DeepMind的AlphaFold 2结合了Transformer(具体是其Evoformer模块)与几何深度学习,解决了生物学中长达50年的蛋白质折叠问题。系统能够仅从氨基酸序列预测蛋白质的三维结构,准确度接近实验方法。
科学语言模型:Galactica、SciBERT等模型在科学文献上预训练,能够执行化学式生成、数学推理、文献摘要等任务,加速科研流程。
代码智能:Codex、AlphaCode等基于Transformer的模型将编程视为一种语言任务,实现了从自然语言描述到代码的生成,在编程竞赛中达到人类中等水平。
大模型时代:生态、能力与社会影响
4.1 技术栈的全面革新
Transformer大模型的兴起推动了AI技术栈的全面革新:
硬件与系统:从通用GPU到专用AI芯片(如TPU、IPU),从单机训练到万卡集群的分布式训练,大规模Transformer训练催生了新的硬件架构和系统软件栈。
训练技术:混合精度训练、激活检查点、模型并行、流水线并行等技术使训练千亿参数模型成为可能;指令微调、人类反馈强化学习等对齐技术改善了模型的安全性和有用性。
推理优化:模型压缩(剪枝、量化、蒸馏)、服务框架(Triton、TensorRT)和专用推理芯片降低了部署成本,使大模型能够服务实际应用。
开源生态:Hugging Face Transformers库成为事实标准,集成了数千个预训练模型;PyTorch、JAX等框架提供灵活的开发体验;模型中心和数据集的开放共享加速了社区创新。
4.2 新兴能力与社会影响
能力涌现的深层含义:大模型展现的涌现能力挑战了我们对智能本质的理解。如果复杂推理、概念组合、代码生成等能力可以从大规模文本中“自发”出现,这对认知科学和教育理论意味着什么?
人机协作新范式:大模型正改变人类与信息系统的交互方式:
-
编程助手:GitHub Copilot等工具提升开发者效率
-
创意伙伴:辅助写作、设计、音乐创作
-
教育导师:个性化辅导和解释复杂概念
-
研究助手:文献整理、假设生成、实验设计
经济与就业影响:AI自动化可能重塑劳动力市场,同时创造新的职业(如提示工程师、AI伦理审核员)。如何确保技术红利广泛共享,是必须面对的社会课题。
风险与治理挑战:大模型带来了新的风险维度:
-
偏见与公平性:训练数据中的社会偏见可能被放大
-
事实准确性:“幻觉”问题在关键应用中的风险
-
安全与滥用:被用于生成虚假信息、恶意代码等
-
环境成本:大模型的训练和推理能耗不容忽视
这些挑战呼唤着新的治理框架,需要技术、政策、伦理等多领域的协作应对。
挑战与未来方向
5.1 技术挑战:效率、推理与鲁棒性
效率瓶颈:注意力机制的O(n²)复杂度限制了长序列处理。线性注意力、状态空间模型(如Mamba)等新架构试图突破这一限制,但在表达能力上仍有妥协。
推理能力:当前模型在复杂逻辑推理、数学证明、因果推断等方面仍有局限。如何将符号推理与神经计算结合,是实现可靠推理的关键方向。
长上下文建模:虽然技术已能处理数十万token的上下文,但真正有效利用长距离依赖仍具挑战。改进的位置编码、层次化注意力等方案正在探索中。
多模态深度融合:当前多模态模型多停留在表面对齐,如何实现深层次的跨模态理解和推理,是通往更通用智能的关键。
5.2 架构演进:Transformer之后是什么?
虽然Transformer仍是主流,但研究社区已在探索后Transformer时代的可能性:
混合架构:结合CNN的局部性、RNN的序列建模和Transformer的全局注意力,创造更具表达力的混合模型。
完全不同的范式:基于状态空间模型(SSM)的Mamba架构在长序列任务中展现了竞争力;基于能量的模型、扩散模型等为生成任务提供了新视角。
神经符号融合:将神经网络的模式识别能力与符号系统的可解释性和推理能力结合,可能是实现可靠AI的必由之路。
生物启发计算:虽然当前AI与大脑工作原理差异巨大,但脉冲神经网络、神经形态计算等方向提供了新的灵感来源。
5.3 迈向通用人工智能:Transformer的角色
Transformer架构在通往通用人工智能(AGI)的道路上扮演着多重角色:
强大的世界模型:通过大规模多模态预训练,Transformer学习了关于语言、视觉、代码等领域的丰富知识,构建了隐式的世界模型。
通用接口与抽象器:Transformer的序列到序列框架可以处理多种模态和任务,提供了统一的计算接口。
认知架构的组件:未来的AGI系统可能包含多个专门化模块,而Transformer很可能作为核心的语言理解、推理或规划组件。
然而,Transformer(至少在当前形式下)可能不是AGI的完整答案。真正的人类级智能需要:
-
具身体验与物理直觉
-
社会情感理解与交互能力
-
因果推理与反事实思维
-
自我反思与元认知能力
-
目标导向的规划与执行
这些能力可能需要新的架构创新和训练范式。
结语:Transformer的遗产与启示
回顾Transformer的发展历程,我们可以总结出几个深刻的启示:
简洁性的力量:Transformer的核心思想——自注意力——在数学上是优雅而简洁的。正是这种简洁性赋予了它强大的表达能力和广泛的适用性。
规模化的重要性:Transformer架构特别适合规模化扩展,无论是模型参数、训练数据还是计算资源。这促使整个领域重新认识规模定律的重要性。
统一化的趋势:从处理单一模态的专门模型,到处理多模态的统一架构,AI领域正朝着更通用、更统一的范式发展。Transformer在这一趋势中扮演了关键角色。
基础研究的价值:Transformer最初是一个基础研究项目,没有直接的应用目标。它的成功再次证明了基础研究的长期价值——可能在不经意间孕育颠覆性创新。
持续的演进:Transformer本身也在不断进化,从原始版本到各种高效变体,从纯文本到多模态。这种持续演进的能力是其生命力的体现。
当我们站在这个AI快速变革的时代节点,Transformer不仅是一个技术架构,更是一面镜子,映照出人类对智能本质的不断探索。它提醒我们,真正的突破往往来自对基础假设的重新思考,来自简单而深刻的核心洞察。
Transformer时代远未结束,它仍在演进、扩展、融合。无论未来会出现什么新的架构范式,Transformer所代表的“关系建模优先”的设计哲学,其对“注意力作为智能核心机制”的探索,都将持续影响人工智能的发展方向。
在通往更智能、更通用的人工智能的道路上,Transformer已搭建了一座坚实的桥梁。而我们,正行走在这座桥上,见证并参与着这一激动人心的历史进程。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)