嵌入式视角下的浮点运算性能之迷
摘要:探讨了嵌入式开发中浮点运算的性能与精度问题。首先分析了浮点数的存储原理,对比定点数的局限性,指出浮点数通过科学计数法实现数值范围的扩展。重点解读了IEEE 754标准对浮点数存储格式的统一规范,包括单精度、双精度等不同格式的应用场景。随后详细剖析了浮点运算单元(FPU)的硬件设计,以加法器和乘法器为例,说明其运算流程和优化思路,包括单路径/双路径加法器的设计差异。文章揭示了FPU如何通过专用
目录
1. 前言
在日常软件开发,尤其是对资源、精度和实时性要求严苛的嵌入式开发领域,“尽量避免浮点运算”几乎是每个开发者都听过的“金科玉律”。
我们常常会陷入这样的纠结:明明用浮点数表示温度、电压、转速等物理量更直观,却不得不费力地用定点数缩放、整数和移位的组合运算来替代——究其原因,大家的共识往往集中在两点:浮点运算“跑不快”,拖慢系统响应;更让人头疼的是它“算不准”,明明简单的加减乘除,结果却可能出现微小偏差。
但同样是二进制数据表示,为什么浮点数就比整数运算“特殊”?是它的存储逻辑天生复杂,还是硬件执行机制存在差异?
更有意思的是,如今不少中高端单片机已经自带了浮点运算单元(FPU),搭载FPU后,浮点运算效率能实现数倍甚至数十倍的提升。这又引发了新的疑问:FPU是如何针对性解决浮点运算的“慢”与“不准”问题的?它的硬件架构设计藏着哪些优化思路?今天,我们就从浮点数的底层存储逻辑说起,一步步揭开这些困扰嵌入式开发者的谜题,看看FPU如何为浮点运算“松绑”。
2. 浮点数的存储
在计算机数据表示的底层逻辑里,定点数(定点小数、定点整数)是入门级的表示方式,但面对实际场景中 “非纯小数、非纯整数” 的数值时,它的短板会立刻暴露,我们看看定点数的局限,以及浮点数是如何解决这个问题的。
定点数的核心特点是小数点位置固定不变,这直接限制了它能表示的数值范围,定点小数只能表示纯小数,定点整数只能表示纯整数。
为了覆盖 “既有整数又有小数” 的数值,计算机引入了浮点数—— 它借鉴 “科学计数法” 的思路,让小数点的位置可以 “浮动”,核心形式是:
数 = 基数ᵉ × 尾数
在二进制的存储中,二进制一般由三部分构成,基数一般为2,指数部分的数称之为阶码E,然后还有尾数M。
比方说二进制浮点数110.0101可以表示成:
110.0101 = 2 10 ∗ 1.100101 110.0101=2^{10}*1.100101 110.0101=210∗1.100101
注意:这里的指数位置10表示的是十进制的2。*
但如果是这样,同一个浮点数可以有多种表示形式:
既然二进制数的底数一般默认为2,也就可以不用专门存储底数,只需要存储阶码和尾数:
- 阶码的位数决定了数据能表示的范围,位数越多,能表示的数值范围越大。
- 尾数的位数决定了浮点数的精度,阶码长度相同时,分配给尾数的位数越多,数据表示的精度就越高。
在不同的表示方式(阶码和尾数的存储尾数不确定)下,浮点数所能表示的最大值和最小值如下:
举个例子,比方说我们的硬件平台二进制数的阶码和尾数分别可以存储三位,那么存储范围如下:
正数 N 最大值: 2 3 ∗ 0.75 正数N最大值:2^{3}* 0.75 正数N最大值:23∗0.75
正数 N 最小值: 2 − 3 ∗ 0.25 正数N最小值:2^{-3}* 0.25 正数N最小值:2−3∗0.25
负数 N 最小值: 2 3 ( − 0.75 ) 负数N最小值:2^{3} (-0.75) 负数N最小值:23(−0.75)
负数 N 最大值: 2 − 3 ∗ ( − 0.25 ) 负数N最大值:2^{-3}* (-0.25) 负数N最大值:2−3∗(−0.25)
很多时候,在不同的硬件平台上,阶码和尾数的存储位数可能不一样,这样就给软件的移植和维护带来很大的麻烦,为了解决这个问题,美国电气电子工程师协会发布了一项标准,称之为IEEE754标准。
3. IEEE754标准
IEEE 754 是1985 年首次发布的浮点数算术标准,核心是统一浮点数的存储、运算和表示规则,全称为 “IEEE Standard for Floating-Point Arithmetic”(IEEE 浮点算术标准)IEEE SA。它由著名计算机科学家William Kahan(被誉为 “浮点数之父”)等人设计,解决了当时计算机浮点数表示和运算缺乏统一标准的问题。
-
💥 核心设计目的
解决浮点数在不同硬件、软件中的表示差异,实现跨平台一致性。
平衡精度、范围和存储效率,适配不同计算场景需求。 -
💥 核心格式与结构
主要定义单精度(32 位)和双精度(64 位)两种常用格式,还有扩展精度格式。
结构统一分为三部分:符号位(1 位,0正1负)、指数位(单精度 8 位 / 双精度 11 位)、尾数位(单精度 23 位 / 双精度 52 位)。 -
💥 关键特性
指数位采用 “偏移值” 存储,避免正负指数的符号处理,扩大表示范围。
尾数位隐含整数位 “1”,以有限位数实现更高精度。
定义了特殊值(如 NaN、正负无穷大),规范异常情况的处理。
IEEE 754标准定义了四种主要的数据格式,嵌入式系统中最常用的是前两种: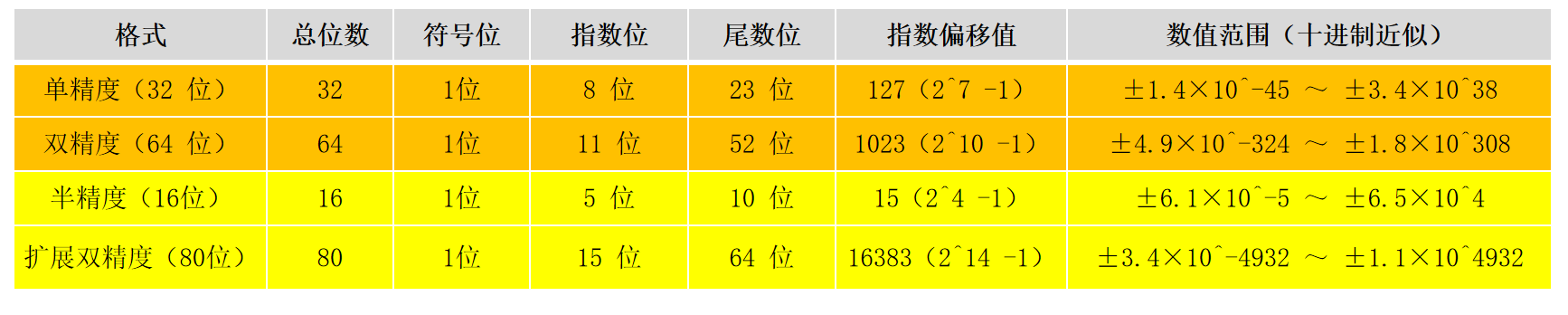
我们可以简单看看后面两种的应用场景:
半精度浮点数 (FP16/Binary16) 的应用领域
半精度浮点数 (16 位) 在以下领域有广泛应用:
-
深度学习与 AI 推理
大模型部署优化:将权重和计算从 FP32 降至 FP16,显存占用减少 50%,数据传输带宽需求降低,推理速度显著提升
混合精度训练:结合FP16和FP32优势,在保持精度的同时加速训练,特别适合 NVIDIA GPU 的 Tensor Core 加速 -
图形处理与渲染
GPU 纹理存储:减少纹理内存占用,提高渲染性能
实时 3D 渲染:在不损失视觉质量的前提下优化性能
VR/AR 设备:降低带宽需求,提升沉浸式体验 -
科学与高性能计算
大规模数据处理:减少存储和传输开销,适合处理天文、气象等大数据集
矩阵计算密集型应用:提升计算效率,如线性代数运算
💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗
扩展双精度浮点数的应用领域
扩展双精度 (通常为 80 位) 主要用于:
-
高精度科学计算
数值分析:求解复杂微分方程、积分计算等需要高精度的场景
物理模拟:量子力学计算、分子动力学模拟等
天文计算:高精度轨道计算、引力模拟 -
金融与财务计算
高精度货币计算:处理大额交易、汇率计算,避免舍入误差
复杂金融模型:期权定价、风险评估等需要极高精度的算法 -
工程与精密测量
航空航天:导航系统计算、轨道规划
精密仪器控制:需要亚微米级精度的设备控制 -
编译器与数学库
浮点运算库:提供高精度中间结果,减少累积误差
科学计算库:如 C/C++ 的long double类型,常实现为扩展双精度
💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗
4. 浮点运算单元的硬件设计
常见的浮点运算有加减乘除4种,我们来看看这些硬件的设计框架是什么样的。
4.1 加法器的硬件设计
需要指出的是,对于计算机而言,正负数只是存储形式上的区别,在运算上并无实质区别,因而并没有专门的减法器。
常见的一种加法器(单路径浮点加法器)的硬件设计如下:
要是单独看这个图可能有点难懂,我们举一个实际的例子,比如现在我们需要进行6.75和-2.25两个浮点数的加法运算,实际的运算过程如下:
A=6.75,换算成2进制就是110.11,B=-2.25,换算成2进制就是-10.01,然后我们转换成IEEE754的表示形式,那么A就会表示成:
2 2 ∗ 1.1011 2^{2}*1.1011 22∗1.1011
B就会表示成:
2 1 ∗ 1.001 2^{1}*1.001 21∗1.001
阶码和尾数就很好计算了,如上图所示。指数求差,求差后得到1,意味着操作数B需要往右移动一位,由于B是负数,所以需要进行求补运算。最左侧的异或操作,决定了是否需要进行求补运算,如果两个操作数同号,则减法运算需要求补,如果两个操作数异号,则加法运算需要求补,这很好理解。
前置工作进行完了,来到了真正的加法,对两个数进行加法运算,运行完的结果是1.00100,求补仍然是1.00100,前导零检测,主要是检测计算结果前面有没有0,如果有,那么属于无效的数据,需要去除,规格化后,结果变成了 2 2 ∗ 1.0010 2^{2}*1.0010 22∗1.0010
还有一个舍入,通俗地说就是保留几位小数,假设我们目前的存储单元是够用的,所以就无须进行舍入操作,再将结果换算成10进制,就是4*1.125=4.5,与我们的理论计算结果一致。
💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗
还有一种设计,就是双路径浮点加法器,双路径法将浮点运算分为Far 路径和Close 路径,两条路径针对不同的运算场景(如操作数指数差 “大” 或 “小”)并行处理:
以 IEEE 754 单精度为例对于单精度浮点数(8 位指数位),常见的阈值选择为 4 或 8(不同处理器设计可能略有差异)
若|EA-EB|≥4,走Far路径,当指数差大时,其中一个操作数的尾数在 “对阶移位” 后会被大量截断(甚至近似为 0),无需复杂的前导零检测,流程更简洁,适合快速处理。
若|EA-EB|<4,走Close路径,当指数差小时,两个操作数的尾数相加后可能产生较多前导零,需要 “前导零预测 / 检测” 来优化规格化过程,流程更复杂但精度更高,适合精细处理。
双路径浮点加法器我们就不举实际的例子了。有了单路径加法器的分析过程,这个加法器的分析也会比较容易。
4.2 乘法器的硬件设计

有了加法器的基础,乘法器反而更简单了,与10进制的运算一样,指数相加,尾数相乘,然后再将结果统一起来就行。指数运算的结果,决定了尾数乘法的移位方向,如果>0,说明需要扩大数值,需要进行左移计算,反之则进行右移计算(如果用小数点的移动方向进行描述,则正好相反,本质都是一样的)。
如加法一样,乘法也举个例子:
我们需要计算0.75*2.5,同样地,先转化成二进制,在转化成IEEE754的存储形式。指数运算的结果是-1,加法运算的结果是1.111(二进制),然后规格化右移,变成0.1111,最终结果就是:
2 − 1 ∗ 1.111 2^{-1}*1.111 2−1∗1.111
将其转换成10进制,就是0.9375,与我们的理论计算结果一致。
4.3 除法器的硬件设计
除法虽然硬件看着简单,但是运算流程上却相对复杂一些,因为除法运算是一次次迭代才能出现最终结果的,并不是像前几个流程一样,数据在每个模块只执行一遍。
该除法器属于恢复余数法除法器,子模块基本功能
-
寄存器 A:存储部分余数,是循环的核心存储单元,结果会反馈到减法器和多路选择器。
-
减法器:执行 “当前部分余数 - 除数 B”,判断是否 “够减”(结果≥0 则够减,否则不够减)。
-
MUX(多路选择器):根据减法结果的符号选输入:
够减:选减法结果作为新余数;
不够减:选原寄存器 A 的值(恢复之前的余数,这是 “恢复余数法” 的核心)。 -
移位器(1bit 左移):对新余数左移 1 位(相当于余数 ×2,为下一次减除数做准备,是除法迭代的必要步骤)。
运算的基本过程是:
取 A 的高位(部分余数)与除数 B 相减。
- 若结果为正或零(符号为 +),则商1,并将减法结果(新余数)左移 1 位,同时 A 的低位左移 1 位,最低位补 1(因为商 1)。
- 若结果为负(符号为 -),则商0,并且不保留减法结果,而是用原来的部分余数左移 1 位(即恢复原余数并左移),A 的低位左移 1 位,最低位补 0。
最后把商再一位位拼接起来。
比如我们现在需要计算5.25÷2.75,前置的转化是这样的:
所以除法运算前也是需要对阶的,在规格化二进制的基础上,再将两个数都*4,A就变成了10101(二进制),B就变成了01011(二进制),现在就可以进行除法运算了。
前几步的运算是这样的: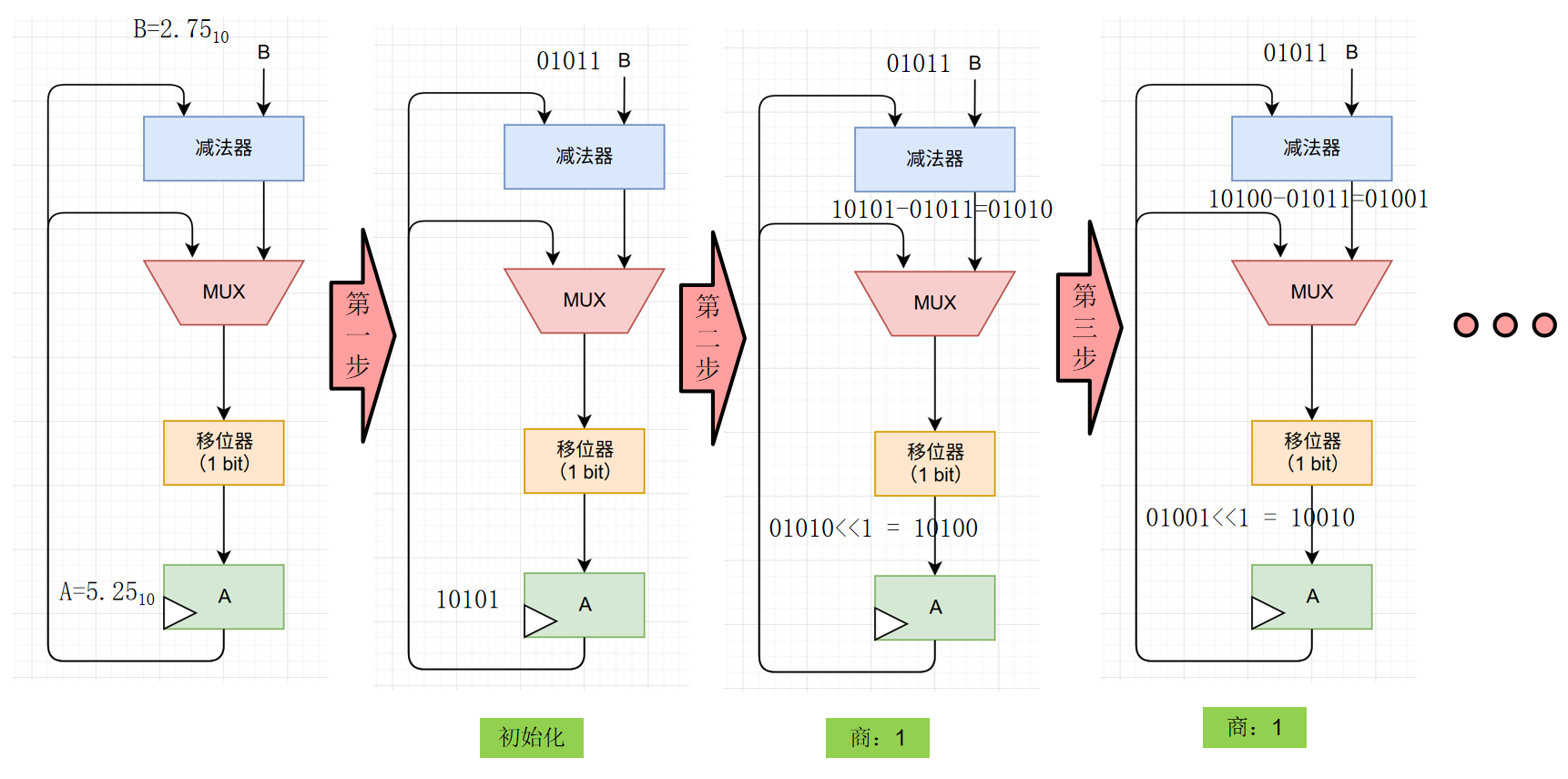
由于迭代次数比较多,所以就不一一列举,只列举流程中一些运算结果: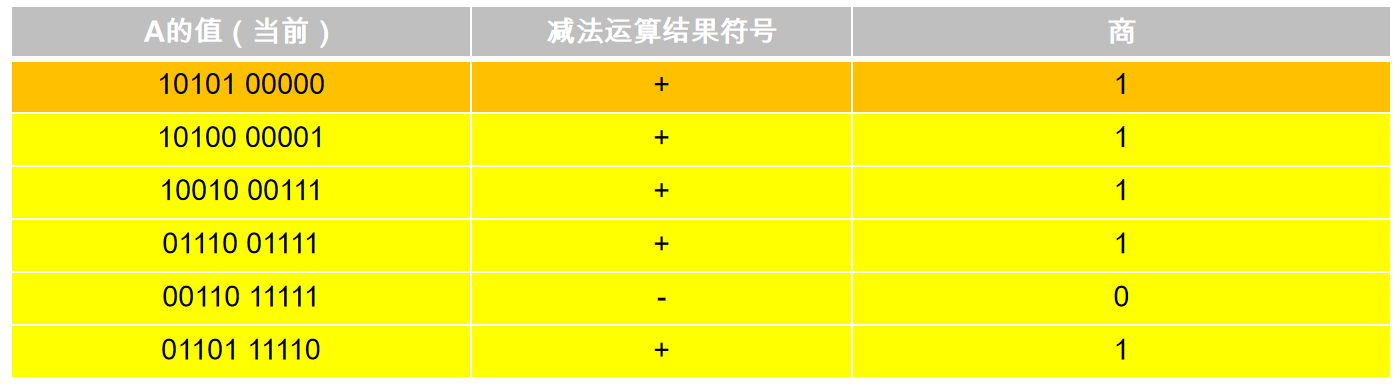
橙色部分是整数的商,黄色部分是小数的商,所以运算结果就是:
1.11101 ( 二进制 ) 1.11101(二进制) 1.11101(二进制)
然后换算成10进制,就是
1.1110 1 2 = 1 + 0. 5 10 + 0.2 5 10 + 0.12 5 10 + 0.0312 5 10 = 1.9062 5 10 1.11101_2=1+0.5_{10}+0.25_{10}+0.125_{10}+0.03125_{10}=1.90625_{10} 1.111012=1+0.510+0.2510+0.12510+0.0312510=1.9062510
我们的理论计算结果是:≈1.90909,如果要更加精确,还可以继续迭代。
💖有一个问题很重要,商的小数点位置是如何确定的?
这个很简单,如果A的当前值是在对阶后,没有移位的原本值,那么商就是其整数部分,反之就是小数部分。比方说迭代的第一步,A的值就是其原本的值10101,所以求得的商就是商的整数部分(类比10进制的除法运算就很容易想明白)。
4.4 浮点运算单元的融合设计
实际的FPU,肯定不可能是以上三个模块的直接拼接,由于以上模块有很多类似,或者相同的操作,比方说前导零检测,舍入操作等,这些模块就可以用共用。
通过以上模块的计算过程可以发现,虽然浮点数分成了阶码和尾数两个部分。但实际运算中,阶码只进行简单的运算,而尾数的运算就相对复杂,因此,在进行融合设计时,一般会将阶码与尾数分开进行处理。
FPU的融合设计架构,大体上由一下几个模块构成:
-
Input Formatter(输入格式化器)
作为流程的起点,它接收两个浮点输入 din0 和 din1,核心作用是解析浮点数的 “指数” 和 “尾数” 部分,并将其分别路由到指数路径和尾数路径,为后续的分路运算做准备。 -
指数路径(Exp + Exp Adjust)
负责浮点数 “指数部分” 的处理,分为两个关键模块:
Exp 模块:对输入的指数部分进行初步处理,为后续的 “指数调整” 提供基础数据。
Exp Adjust 模块:根据具体的运算类型(如加法、乘法、除法等),对指数执行针对性调整。例如:
加法 / 减法需要 “对阶”(使两个操作数的指数相同);
乘法 / 除法需要 “指数相加 / 相减”;
调整后的指数将用于最终的结果组装。 -
尾数路径(Mantissa Path,红色虚线框内)
负责浮点数 “尾数部分” 的运算、规格化和舍入,是浮点运算的核心计算区:
多运算路径(add path、mul path、div/sqrt path、misc path):根据运算类型(加法、乘法、除法 / 平方根、其他杂项操作),选择对应的路径对尾数执行运算。
多路选择器:选择对应运算路径的尾数结果,送入后续的规格化和舍入流程。
Normalize(规格化):将运算后的尾数调整为标准浮点数形式(如使尾数落在 [1, 2) 区间内,除非是非规格化数),保证浮点数的表示符合规范。
Rounding(舍入):对规格化后的尾数进行舍入操作,以匹配浮点数的精度要求(如单精度、双精度),常见舍入策略包括 “最近舍入”“向零舍入” 等。 -
Output Formatter(输出格式化器)
将指数路径调整后的指数和尾数路径处理后的尾数重新组合,封装成标准的浮点数格式,最终输出为 dout。
5. 软硬件浮点加法运算的性能对比
前面我们进行了很多的理论分析,下面我们做一组实验,对比一下,相同的浮点运算,用不用FPU,性能差距到底有多大。
由于时间的原因,只进行了浮点运算的加法实验,并未设计浮点的减法和乘除法相关实验。
我们采用的硬件平台是英飞凌CYT2B6系列MCU,该MCU配有单精度浮点运算单元(M4内核)。采用的IDE是嵌入式开发中最常用到的Keil 5。
5.1 Keil浮点运算配置方法
要想开启硬件浮点运算,只需要在选项的编译(CC)和链接(Linker)标签页中加入
-mfloat-abi=hard-mfpu=fpv4-sp-d16
即可。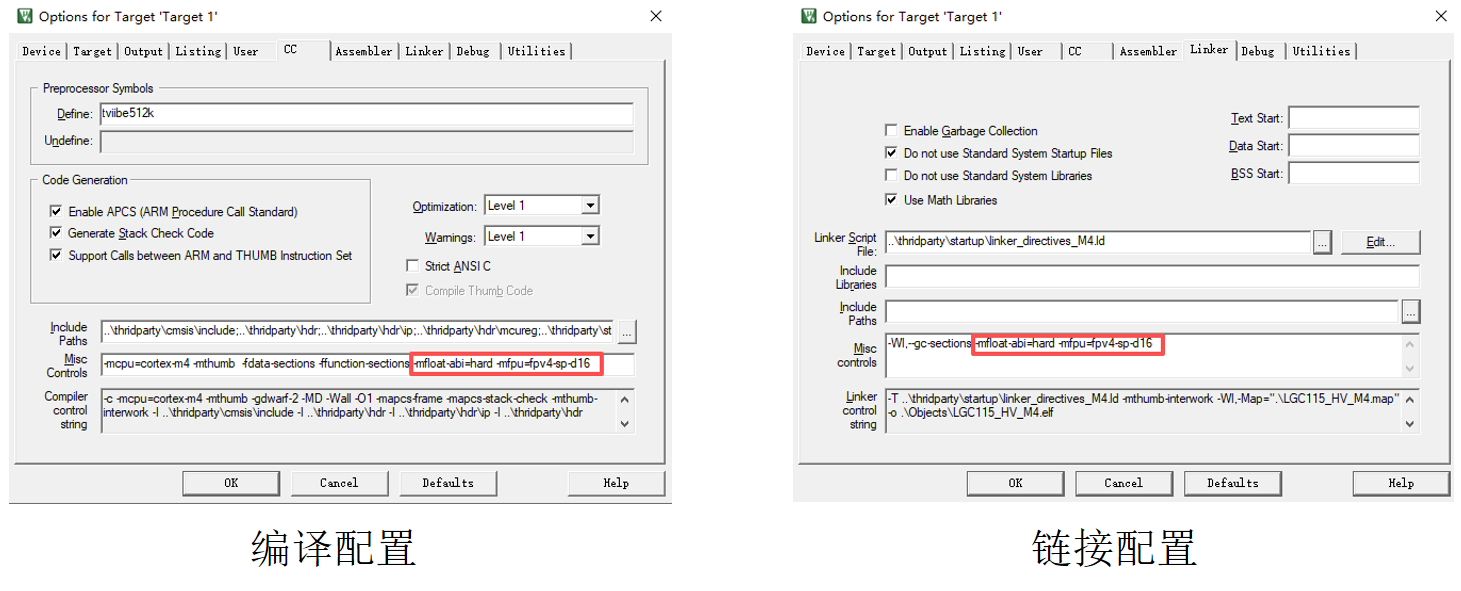
其中:
-
-mfloat-abi=hard:指定浮点 ABI,控制函数调用约定ABI(Application Binary Interface,应用二进制接口)是编译器、链接器、程序之间的 “二进制交互规则”,核心包括:函数参数传递方式、寄存器使用、栈布局、数据类型对齐等。
-
-mfpu=fpv4-sp-d16:指定FPU型号,控制浮点指令生成,目标 MCU 的 FPU 具体型号和能力,编译器据此生成直接操作 FPU 的硬件指令(而非软件模拟)。

5.2 汇编指令对比
在一个固定周期的task(10ms)中,我们撰写一个最简单的单精度浮点加法运算程序:
static void Sys_task_10ms(void)
{
volatile float a = 3.5;
volatile float b = -2.25;
volatile float b = -2.25;
sum = a + b;
}
再来写一个简单的双精度浮点加法:
static void Sys_task_10ms(void)
{
volatile double a = 3.5;
volatile double b = -2.25;
volatile double b = -2.25;
sum = a + b;
}
我们来看看在debug的时候,开启与关闭浮点运算单元,生成的汇编指令有什么不同:
5.2.1 关闭FPU
在不启用FPU的时候,我们先看看单精度浮点运算生成的汇编指令:
249: sum = a + b;
0x10021670 9803 LDR r0,[sp,#0x0C]
0x10021672 9902 LDR r1,[sp,#0x08]
0x10021674 F001FDAA BL.W 0x100231CC __aeabi_fadd
0x10021678 9001 STR r0,[sp,#0x04]
很显然,浮点加法的汇编指令是__aeabi_fadd,什么是__aeabi_fadd呢?
__aeabi_fadd是 ARM 统一的浮点加法接口,和高级语言封装函数的逻辑完全一样,这样做出于以下几点考虑:
- 避免重复写代码:浮点加法需要几十条基础指令,如果每次加浮点数都手写这几十条,代码会无比臃肿;封装成__aeabi_fadd,每次调用只需一条BL指令即可;
- 符合统一规范:ARM 定义 EABI 规则,让不同编译器(TI CCS、GCC)、不同厂商的库(TI 的 MSPM0 库、ARM 的 CMSIS 库)都认__aeabi_fadd这个名字,保证代码可移植;
- 适配硬件差异:有 FPU 的内核(如 M4F),__aeabi_fadd里只需要 1 条VADD.F32硬件指令;无 FPU 的 M0+,就用几十条基础指令模拟 —— 但对外的调用方式(BL __aeabi_fadd)完全不变,上层代码不用改。
这条汇编指令,就相当好多条基础的汇编指令,类似于C语言的函数(接口)。我们看看这里面都有些什么?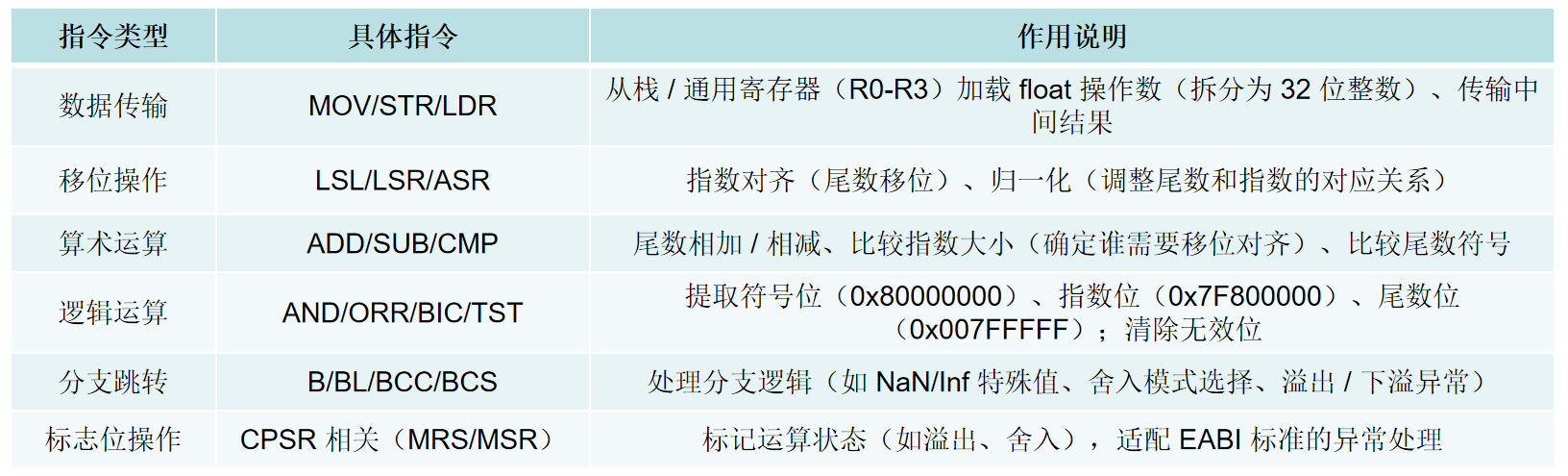
将浮点运算拆分成了很多很多基础汇编指令,这也是在运算平台在不配备(不开启)FPU时的常见方案:软件模拟FPU对数据进行处理。
我们再来看看双精度浮点运算生成的汇编指令:
249: sum = a + b;
0x100216B4 E9DD0104 LDRD r0,r1,[sp,#0x10]
0x100216B8 E9DD2302 LDRD r2,r3,[sp,#0x08]
0x100216BC F001FDA8 BL.W 0x10023210 __adddf3
0x100216C0 E9CD0100 STRD r0,r1,[sp,#0]
显然已经不一样了,此时的加法指令变成了__adddf3函数,__adddf3是GNU libgcc 的双精度软浮点加法函数,GCC 的libgcc库为软浮点运算定义了一套函数命名规范,格式为:
[ 操作 ] [ 精度 ] [ 参数数 ] [操作] [精度] [参数数] [操作][精度][参数数]
- add:表示加法(sub = 减法、mul = 乘法、div = 除法);
- df:double float的缩写,代表双精度浮点(64 位,double 类型);
对应地,sf代表single float(单精度,32 位,float 类型); - 3:表示 “三操作数”(两个源操作数 + 一个结果操作数),是 libgcc 的命名惯例。
此时,由于并未启用FPU,仍然软件模拟FPU对数据进行处理。
5.2.2 启用FPU
现在我们参照5.1的操作方法,启用FPU,看看汇编会不会有所不同。
先来看单精度浮点运算:
249: sum = a + b;
0x1002169C EDDD7A03 VLDR s15,[sp,#0x0C]
0x100216A0 ED9D7A02 VLDR s14,[sp,#0x08]
0x100216A4 EE777A87 VADD.F32 s15,s15,s14
0x100216A8 EDCD7A01 VSTR s15,[sp,#0x04]
显然,此时汇编指令已经变成了VADD.F32,此时便可直接将浮点数提交到FPU中进行处理。究竟有没有在FPU中进行处理,我们在后续的5.3中,通过一个简单的时间,对比一下性能就能明显看出来。
再来看看双精度的浮点运算:
249: sum = a + b;
0x100216B4 E9DD0104 LDRD r0,r1,[sp,#0x10]
0x100216B8 E9DD2302 LDRD r2,r3,[sp,#0x08]
0x100216BC F001FDA8 BL.W 0x10023210 __adddf3
0x100216C0 E9CD0100 STRD r0,r1,[sp,#0]
与关闭FPU相比,并没什么两样,可见对于双精度浮点运算,该单片机的FPU并未参与其中,这也很好地验证了手册中的说法。
5.3 FPU提升效率的核心原因
- 运算方式的底层差异🚩
无 FPU 时:MCU 只能靠 CPU “软件模拟” 浮点运算 —— 需把浮点操作拆成数十条整数运算、移位、逻辑判断指令(比如单精度加法要 30 + 条 CPU 指令),每一步都占用 CPU 周期,耗时极长。
有 FPU 时:FPU 是专用硬件电路(内置浮点寄存器、专用运算单元),可通过单条浮点指令(如 ARM 的VADD.F32)直接完成操作,多数场景仅需 1~3 个 CPU 周期,无需拆分步骤。 - CPU 资源的占用逻辑🚩
软件模拟浮点时,CPU 会被浮点任务 “独占”:不仅运算本身慢,还会阻塞中断响应、外设控制等其他任务,降低 MCU 实时性。
FPU 可与 CPU并行 / 协同工作:CPU 执行普通指令时,FPU 可同时处理浮点运算;即使串行,FPU 的硬件加速也能大幅减少 CPU 的 “无效占用”。
这也揭示了计算机/计算单元设计的基本哲学:空间换时间。在内核设计中,加入FPU,牺牲了一些物理空间,换取了运算效率上的提升。
这种设计哲学也贯穿了GPU的设计,有兴趣可以看看我的另一篇帖子:万字长文:英伟达 GPU 硬件架构发展史全景回顾
5.4 浮点性能对比
现在我们设计程序,测量一条浮点运算的C语句需要多少时间,由于一条C语句太快,不方便测量,因此我们可以对以上的语句再做一些调整:
对于单精度的运算:
volatile float arr[2] = {3.5f, -2.25f};
volatile float sum =0;
for(int i = 0; i < 10000; i++)
sum = arr[0] + arr[1];
对于双精度的计算:
volatile double arr[2] = {3.5f, -2.25f};
volatile double sum =0;
for(int i = 0; i < 10000; i++)
sum = arr[0] + arr[1];
时间测量方法:利用系统定时器,或者自己引test pin,然后用示波器测电平的方法都可以。
先分别在开启和关闭浮点运算单元的情况下,测试以上代码的执行时间,然后将浮点加法运算替换成空语句,二者作差,就算出了浮点加法运算的净时间。
经测量:
关闭FPU单精度浮点的加法运算净耗时:5025 us
开启FPU单精度浮点的加法运算净耗时:575 us
关闭FPU双精度浮点的加法运算净耗时:7675 us
开启FPU双精度浮点的加法运算净耗时:7675 us
可见:对于单精度,硬件浮点的加法运算速度大约是软件浮点的10倍,而对于双精度,由于FPU并未发挥作用,因而用时一致。
6. 拓展问题
6.1. 拓展问题1
对于有浮点运算单元(FPU)的MCU来说,执行一次运算往往需要比较久的时间,如果在此期间发生了中断,会不会对原来的操作数或中间运算结果会不会产生影响?
- 硬件自动保存机制
大多数 MCU (如 ARM Cortex-M 系列) 在中断发生时,仅自动保存通用寄存器(R0-R3, R12, LR, PC, xPSR),不会自动保存浮点寄存器(S0-S31 和 FPSCR)。
FPU 寄存器组包括:
32 个单精度浮点数据寄存器 (S0-S31)
浮点状态控制寄存器 (FPSCR):包含舍入模式、异常标志等关键状态
- 中断对 FPU 的具体影响
如果中断处理程序不使用 FPU:
FPU 寄存器值保持不变,不影响原浮点运算
Cortex-M 处理器的 “惰性堆叠” 机制会检测并跳过 FPU 寄存器保存,提高中断响应速度
如果中断处理程序使用 FPU:
若未保存原 FPU 上下文,新运算会直接覆盖原 FPU 寄存器内容,导致原运算结果完全丢失
即使中断处理程序未显式使用 FPU,编译器优化或库函数调用也可能隐式使用 FPU,造成数据破坏
什么又是惰性堆叠呢?
“惰性堆叠(Lazy Stacking)” 也常被译作 “惰性压栈”,是 ARM Cortex-M 系(M4/F7/H7等带 FPU 的内核)针对浮点单元(FPU)上下文 的硬件级优化机制,核心是:中断发生时,不无条件保存 FPU 寄存器,而是 “按需保存”—— 只有真正需要使用 FPU 时,才保存 / 恢复主线程的 FPU 上下文,以此减少中断延迟、提升响应速度。
6.1. 拓展问题2
在具有浮点运算单元的MCU中,一般浮点运算都会有舍入操作,那么一般会是哪种舍入方式?软件可配置吗?这种方式和硬件平台有关吗?
-
默认舍入方式:遵循
IEEE 754标准,几乎所有 MCU 的 FPU 默认采用就近舍入(四舍六入五取偶); -
软件可配置性:支持!通过修改 FPU 专用状态控制寄存器(如 Cortex-M 的 FPSCR、x86 的 MXCSR)实现,无需硬件改动;
-
与硬件平台的关系:硬件平台(FPU 架构)决定(是否支持 IEEE 754 全量舍入模式),但主流架构(ARM Cortex-M4/M7/M33、RISC-V RV32F/RV64F、x86)均支持完整配置,仅低端 FPU 可能存在功能裁剪。
7. 参考文献
- 《AI处理器硬件架构设计》,任子木,李东声,机械工业出版社2025.4
- 《计算机组成原理微课堂》,湖科大教书匠,哔哩哔哩
- 英飞凌MCU数据手册:infineon-cyt2b6-datasheet-32-bit-arm-r-cortex-r–m4f-microcontroller-traveo-tm-ii-family-datasheet-en.pdf
- 德州仪器MCU数据手册:MSPM0 G 系列 80MHz 微控制器.pdf

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)