AI芯片名词解释
1. EBIT贡献指的是一个业务单元(如子公司、产品线、事业部、地区分公司等)为整个企业的总营业利润所做出的贡献额。2. EBIT贡献 = 该业务单元的营业收入 - 该业务单元的直接营业成本与费用3. 剥离掉总部的各种分摊和财务结构,你这个业务部门自己到底赚了多少钱?
·
服务器名词解释
什么是EBIT贡献
1.EBIT贡献指的是一个业务单元(如子公司、产品线、事业部、地区分公司等)为整个企业的总营业利润所做出的贡献额。
2. EBIT贡献 = 该业务单元的营业收入 - 该业务单元的直接营业成本与费用
3.剥离掉总部的各种分摊和财务结构,你这个业务部门自己到底赚了多少钱?
AMD Instinct MI308
- AMD Instinct MI308 是一款专为人工智能和高性能计算设计的加速器芯片。
- 强大的计算能力与内存配置:MI308拥有庞大的计算单元和高容量的HBM3显存。这使得它尤其适合处理大规模语言模型,因为大容量的显存能够容纳更多的模型参数,减少与系统内存的数据交换,从而提升计算效率。
- 先进的小芯片设计:它采用了与MI300X相同的小芯片(Chiplet)设计。这种设计允许将不同功能的芯片模块集成在一个封装内,有助于提升芯片性能、良品率并控制成本。
- 专为中国市场的合规设计:MI308是AMD为了在遵守美国出口管制的前提下重返中国市场而专门设计的降规版本。通过对核心数量、频率或带宽等参数进行适当下调,确保其性能不触及出口门槛。尽管如此,它依然旨在满足中国国内市场对AI算力的强劲需求。
人工智能(AI)芯片 B30A
- B30A的设计体现了英伟达在技术、市场与政策间寻求平衡的策略。
- 架构与性能:B30A从H20的Hopper架构升级至Blackwell架构,这带来了显著的性能提升。据报道,其FP8算力超越H20,并且在处理AI训练任务时,凭借架构优势,实际有效算力最高可达H20的1.3倍。
- B30A采用单芯片设计,这不仅是降低成本的手段,更是为了符合美国的出口管制规定,因为旗舰级B300采用的是被限制的双芯片设计。此外,为了精准满足合规要求,传闻B30A还采用了分频传输等特殊技术,以在保持高逻辑带宽的同时,将物理带宽控制在限制阈值以内
- 优化AI工作负载:新的Blackwell架构集成了Transformer引擎,能显著提升大语言模型的训练和推理效率。同时,第四代NVLink技术提升了多卡互联的能力,有助于构建更强大的计算集群。
近封装光学(NPO)和及共封装光学(CPO)的异同
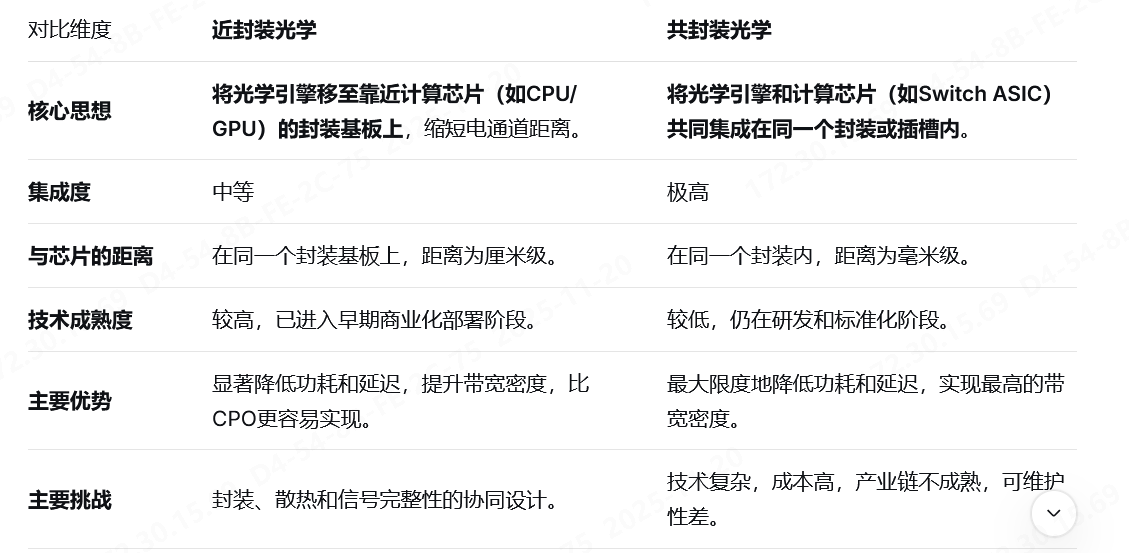
- 总而言之,NPO和CPO的核心相同点在于都通过将光学引擎靠近芯片来突破“功耗墙”和“带宽墙”。它们的根本区别在于集成的“亲密程度”:NPO是“邻居”关系,而CPO是“同居”关系。目前,产业界正沿着NPO的路径稳步推进,同时为最终的CPO时代进行技术储备。(演化路径是可插拔光学->NPO-CPO的方向)
AIGC(Artificial Intelligence Generated Content)
- 它指的是通过各种人工智能技术,自动创建或生成的各类数字内容。这些内容可以包括文本、图像、音频、视频、代码、3D模型等。
- 让AI从“内容的理解者”转变为“内容的创造者”。
AIGC的爆发主要得益于深度学习,特别是以下两类模型:
- 生成式模型:这是AIGC的核心。与只能进行“分类”或“预测”的判别式模型不同,生成式模型学习大量现有数据的分布规律,然后从中学习“创作”,生成全新的、与训练数据相似但又不完全相同的内容。
- 生成式预训练变换模型(GPT):由OpenAI推广开来的这一架构,是当前大多数AIGC应用(尤其是文本类)的基础。它通过“预训练”在海量数据上学习语言规律,再通过“微调”和“提示工程”来执行具体的生成任务。
世界模型
- 简单来说,世界模型 是指一个系统(可以是生物大脑或人工智能体)为了理解和预测外部世界而构建的内部模型。它是对外部环境如何运作的一种压缩的、抽象的内部表示。
- 核心思想:系统不是对每一个感官输入都做出即时反应,而是通过在内部模拟“可能发生什么”,来更高效、更安全地进行推理、规划和决策。
同比和环比
- 同比:与历史同期相比
含义:通常指今年某特定时期(如本月、本季度)与去年的同一时期进行比较。
目的:为了消除季节性变动的影响,反映出在相同季节或周期背景下的真实增长情况。例如,比较今年春节期间的销售额与去年春节期间的销售额,就避免了春节假期对不同月份的影响。 - 环比:与紧邻的上一个时期相比
含义:指本期数据与上一个相邻时期(如上个月、上一个季度)进行比较。
目的:为了反映数据的短期趋势和连续变化情况,看发展速度是加快了还是放缓了。
一致预期和指引预期
- 一致预期
含义:指由多家金融机构的分析师(如券商研究所)对某家上市公司未来的关键财务指标(如营收、净利润、每股收益EPS等)进行预测后,所计算出的平均值或中位数。
来源:卖方分析师(Sell-side Analysts)群体。数据服务商会收集所有分析师的预测,然后汇总成一个“市场一致预期”。
本质:它是金融市场对公司业绩的“集体智慧”或“平均看法”。 - 指引预期
含义:指上市公司管理层自身向市场公开提供的、关于公司未来一段时期(如下一个季度或财年)业绩的官方展望或预测。
来源:公司本身(通常通过财报电话会议、业绩发布会或新闻稿等形式发布)。
本质:它是公司内部人对自身业务前景的“官方表态”或“内部目标”。
GAAP(Generally Accepted Accounting Principles),Non-GAAP(Non-Generally Accepted Accounting Principles)
- GAAP
中文:公认会计准则
含义:这是一套由美国财务会计准则委员会制定的、所有美国上市公司必须遵守的、统一的会计规则和标准。
目标:确保财务报表的一致性、可比性和可靠性,让不同公司的财务数据可以在同一标准下进行比较。它侧重于合规性和标准化。
2.Non-GAAP
中文:非公认会计准则
含义:指公司在发布财报时,在GAAP准则的基础上,自行调整和计算的财务指标。
目标:管理层认为这些调整能更好地反映公司核心业务的持续经营业绩,剔除他们认为“一次性”或“非现金”的干扰项。它侧重于展示公司的运营核心表现。
EPS(Earnings Per Share),市盈力

- 市盈率 = 股价 / EPS

看图说话
营收:公司各个项目总收入(比如NVIDIA 数据中心,游戏,可视化,自动驾驶,原设备制造等收入)
毛利润 = 营收- 成本支出(各种供应商钱款等)
营业利润 = 毛利润 - 营业支出(研究开发,销售,综合事务,行政费用)
净利润 = 营业利润-税收(国家交税)
华为Flex:ai 和英伟达 run:ai 分析对比
1.华为 Flex:ai : 异构算力资源统一调度平台,构建跨品牌,环境的统一资源池管理 2. 英伟达 Run:ai : AI工作负载全生命周期编排平台,专注于最大化NVIDIA GPU生态的效率和价值。
google TPU Command Center
TPU Command Center”(或称TPU命令中心)是谷歌推出的一套软件平台,是其“TPU@Premises”新计划的核心组成部分。它的战略意图非常明确:降低开发者使用谷歌TPU硬件的门槛,挑战英伟达在AI计算领域依托CUDA软件建立的生态系统优势.
% YOY 和 % QOQ 含义对比
- % YOY 表示将当前时期(如本月、本季度)的某个数据,与上一年同一时期的数据进行比较,并用百分比来呈现这种变化的幅度。
- % YOY = ((本期数值 - 去年同期数值) / 去年同期数值) × 100%
- % YOY 是洞察数据长期趋势、剔除季节噪音的“金标准”。当你想判断一个公司、一个行业或一个经济体的真实增长动力时,同比(% YOY)是最可靠的分析起点之一。
- 反映数据在短期(一个季度内)的最新变化趋势和波动
- QoQ增长率 = ((本季度数值 - 上季度数值) / 上季度数值) × 100%
- QoQ 是洞察业务短期脉搏、及时响应市场变化的灵敏“仪表盘”,但解读时必须考虑其季节性特点,最好与能排除季节影响的YoY(同比)指标结合分析。
NVIDIA A100
- A100是一款基于Ampere架构的数据中心级GPU,一台强大的超级计算引擎,专为处理人工智能模型训练、科学模拟和海量数据分析等繁重任务而设计。
- 其特点是专为AI运算优化的核心,可将一块物理GPU 安全分割成最多7个独立实例,允许多用户/任务共享一张GPU,极大提升利用率,并确保服务质量。
- 有40GB和80GB HBM2e两种高性能显存版本,80GB 显存带宽超过2TB/秒,能够容纳更大的模型和数据集,解决海量数据吞吐瓶颈,
- GPU间高速互联技术,总带宽高达600GB/s,让多张卡协作像一台更加强大超级GPU 效率大幅提升。
- 擅长大规模AI模型训练与推理,高性能计算,高性能数据分析。
NVIDIA H100
- nvidia H100 数据中心级GPU, 基于全新Hopper架构,专为处理超大规模的人工智能(AI)训练,推理及高性能计算(HPC)任务而设计。与A100 是代飞跃,核心目标突破万乙级参数大模型的计算瓶颈。
- 工艺4ns,集成800亿晶体管,主要配备80GB HBM3显存,带宽达到3.35TB/s,支持nvlik, GPU间互联带宽900GB/s,支持PCIe5.0接口。
- 功耗700W,主要特点有Transformomer引擎,能够智能,动态的在FP8和FP16精度之间切换,相比A100性能有很大的提升
- 新一代NVLink与NVSwitch 将多GPU之间通信提升900GB/s,结合第三代NVSwich 可以构建多达256个GPU(32节点)的庞大集群,更像是一个巨型GPU一样高效协作,专为万亿参数模型训练。
- MIG技术可以将一块物理H100 GPU安全分割为最多7个独立实例。每个实例具备独立的计算、显存和带宽。这极大地提升了云服务商和企业的GPU资源利用率与多租户隔离能力。
- 内建机密计算:H100是全球首款支持硬件级机密计算的GPU,可以在一个受硬件保护的可信执行环境中运行AI和HPC工作负载,确保数据和代码的机密性与完整性。
NVIDIA H20/H20E
- NVIDIA H20/H20E 针对中国特供版芯片,其架构采用Hopper架构,基于台积电4nm 工艺,显存采用 96GB HBM3,带宽4.0TB/s, 功耗400GB, 互联技术 支持NVlink 900GB/s, 其算力相比H100 消减70%,CUDA 核心数量也大幅消减。 但是其补充强化显存H100 显存是
80GB, H20/H20E 显存容量96GB和更高带宽。使得其处理超大显存的大语言模型任务时,反而得心应手。 - 应用场景分析:
大规模AI推理,垂直行业模型训练,前沿大模型训练。
NVIDIA B200(8Hi)
- NVIDAI B200(8Hi) 采用8层堆叠HBM3e 高带宽内存,其显存容量是192GB和带宽8TB/s . 核心架构:Blackwell, 采用 Chiplet/MCM(多芯片模块) 设计,制造工艺台积电4nm 工艺, 显存容量: 92GB HBM3e (8-Hi 堆叠), 带宽高达 8 TB/s, 互联技术,第五代 NVLink, GPU间互连带宽 1.8 TB/s 。单卡功耗1000w 。
- 革命性的Chiplet架构:与之前的单一巨型芯片不同,B200通过先进封装将两个大型计算Die集成在一起。这是英伟达为了突破芯片制造尺寸极限、继续提升集成度的必然选择,可以理解为将“一个超大的GPU”拆分成“两个依然巨大的GPU”协同工作
- 前所未有的功耗与散热,B200的系统级解决方案(如DGX B200、HGX B200服务器)普遍采用先进的液冷技术来确保稳定运行。
- NVIDIA HGX B200 ,节点内集成8块B200 GPU,五代NVLink和NVSwitch实现高达1.8TB/s的高速互连。
- NVIDIA DGX B200 :除了包含8块B200 GPU,还集成了CPU。
应用场景:
前沿大语言模型的开发与训练
超大规模的生成式AI推理
复杂的科学计算与数字孪生
NVIDIA GB200(2x GPU 8Hi)
- GB200是由2个B200 Blackwell GPU + 1个NVIDIA Grace CPU
- 封装与互联:NVLink-C2C(芯片到芯片)技术,提供 900 GB/s 的双向带宽
- GPU 显存(2x)192GB HBM3e (每个GPU 96GB, 8层堆叠), 带宽 8 TB/s
- 480GB LPDDR5X, 带宽 512 GB/s.
- 整个GB200超级芯片功耗约为 2700W
GB200 NVL72
- 在一个液冷机架中,集成72个B200 GPU(36颗GB200 超级芯片)和36个Grace CPU,通过第五代NVLink和NVSwitch将所有72个GPU连接成一个“单一巨型GPU”,用于处理万亿参数大模型.
- GB200 NVL36,机架中集成36个B200 GPU(18颗GB200超级芯片)和18个Grace CPU
应用场景
- 为MoE模型而生:架构针对“混合专家”(MoE)模型进行了极致优化。72个GPU组成的巨大共享内存和高达130 TB/s的NVLink互连带宽,能有效解决MoE模型在GPU间通信和参数加载的瓶颈,实现高达10倍的推理速度提升。
- 全栈协同设计:这不仅是一个硬件产品。从GPU、CPU、NVLink互连到液冷散热,再到NVIDIA TensorRT-LLM等软件栈,构成了一个深度集成的全栈解决方案,以实现极致性能。
- 应用场景:主要用于训练和部署前沿的生成式AI模型(如DeepSeek-R1、Kimi K2 Thinking),也适用于大规模科学计算和数据处理。亚马逊、谷歌、微软等主要云服务商已将其部署于云端
NVIDIA B300(12Hi)
- 采用Blackwell Ultra 架构,制造工艺台积电4NP工艺,288GB HBM3e (12-Hi),带宽维持 8 TB/s,功耗,高达 1400W。
- 互联技术:第五代NVLink,支持“NVLink NVL72”机架级全互联,搭载800G ConnectX-8网卡,提供双倍横向扩展带宽。
- 散热方面: 全部采用全液冷扇热方法。
- 模块化供应策略:英伟达改变了GB200时期提供完整主板的策略。对于GB300超级芯片,英伟达主要提供核心的SXM Puck模块(含GPU)、Grace CPU和基板管理控制器,而将主板设计、内存等组件的采购权更多下放给客户和ODM厂商。这给了超大规模数据中心(如亚马逊、谷歌)更大的定制化自主权。
GB300(2x GPU - 12Hi)
- 2颗 B300 (Blackwell Ultra) GPU + 1颗 Grace CPU
- GPU 显存: 每颗GPU配备 288GB HBM3e (12-Hi),带宽8TB。
- 功耗:B300 GPU功耗达1400W
- 通过NVLink-C2C技术连接,GPU与CPU间带宽900GB/s。
- 散热:与GB200的整块冷板不同,GB300可能采用为每个GPU/CPU独立设计的冷板,以应对更高的散热密度。同时,GB300的电源管理系统全面升级,超级电容UPS和备用电池单元有望成为标配,确保高功耗下的系统稳定与数据安全
GB300 NVL72
- 机柜集成了36个GB300超级芯片(共72个B300 GPU和36个Grace CPU,第五代NVLink和NVSwitch技术,所有72个GPU被连接成一个统一的、可视为单个巨型GPU的庞然大物,用于处理万亿参数级别的模型。
NVIDIA RV200(2x GPU - 12Hi)
- Vera Rubin 架构, R200,下一代NVIDIA 平台架构,其核心构成是 双计算芯片设计(2x GPU Die),芯片级多die设计。系统显存,HBM4 (预计12-Hi堆叠), 容量预计288GB,支持下一代NVLink,保障GPU间极高带宽互联,适用于Decode阶段, 制造工艺台积电3np ,更加先进制程。
- 相比前代GPU 使用了Prefill (预填充),Decode (解码), Prefill 填充阶段使用GDDR7 作为缓存, Decode 阶段使用HBM4 作为缓冲极大提升了内存利用效率。
AMD MI300
- AMD Instinct MI300系列是AMD为挑战英伟达(NVIDIA)在AI加速器领域主导地位而推出的关键产品,核心是通过APU(加速处理单元)架构和192GB超大HBM3显存来提供差异化方案。
- MI300A(APU 加速器):核心构成CPU+GPU+HBM3 的异构APU平台,24各Zen 4核心,显存系统128GB, 晶体管数量约1460亿个。封装技术采用3.5D 混合键合封装。
- MI300X(GPU极速器): 核心构成纯GPU,专为计算密集型任务优化,显存系统192GB HBM3, 显存带宽5.2-5.3TB/s, 晶体管数量约1530亿个, 采用3.5D混合键合封装。
核心架构与关键技术
- 创新的“3.5D”封装技术:该系列是AMD首款采用此技术的产品,将CPU、GPU和HBM3内存通过2.5D硅中介层和3D铜混合键合工艺集成在单一封装内。这种设计极大地缩短了芯片间的互连距离,实现高带宽和低延迟通信。
- 领先的显存系统:这是MI300X最突出的优势。高达192GB的HBM3显存和超过5.2TB/s的带宽,远超同期竞品H100的80GB和3.5TB/s
- 统一的软件栈ROCm:AMD通过开放的ROCm软件平台(特别是最新版ROCm 6)来挑战英伟达CUDA的生态。ROCm 6针对大模型进行了优化,并能与主流开源框架兼容,旨在降低开发者的迁移门槛。
应用表现与市场定位
- 性能亮点: 根据AMD及第三方测试,MI300X在运行DeepSeek-R1等大模型进行推理时表现出色,凭借其大显存和优化软件,在高并发场景下吞吐量可达英伟达H200的5倍。
- 市场目标:MI300X旨在成为数据中心AI加速器的“第二选择”,主要为那些寻求性能和成本平衡。
- 主要挑战:当前面临的最大挑战并非硬件性能,而是英伟达CUDA生态的统治力。成熟的AI软件生态和开发者社区是英伟达短期内难以被撼动的护城河。
AMD MI325X
- AMD MI325X 是AMD在2024年10月发布的AI加速器,定位是MI300X的“内存增强版”,主打升级了256GB HBM3e显存来提升推理性能,从而直接对标英伟达的H200。
- 核心架构: AMD CDNA3, 采用3.5D封装,晶体管计算单元 1530亿个晶体管,304个计算单元,显存系统256GB HBM3e (8颗32GB模组),带宽6TB/s,功耗达到1000w, 互联技术Infinity Fabric。
核心架构与关键技术
- 以最小架构改动,换取对大模型推理性的最大提升。
- 升级内存,剑指推理:升级点是将显存容量从MI300X的192GB提升至256GB HBM3e,带宽也小幅提升至6TB/s。在运行Llama 3.1 70B等大模型进行推理时,相比英伟达H200能实现高达20%-40%的性能领先。
AMD MI355X
- AMD Instinct MI355X 其核心定位是直接挑战英伟达Blackwell B200/GB200系列,核心策略是通过创新的CDNA 4架构、高达288GB的HBM3e显存以及更高的性价比来争夺AI计算市场。
- AMD MI355X CDNA 4 架构, 台积电 3nm 晶体管数量1850亿,显存288G, 显存带宽8TB/s,功耗1400w, 冷却方式直接液冷。
核心架构与关键技术
- 架构与工艺跃升:首次采用基于3nm制程的CDNA 4架构,并采用3D先进封装技术,实现了更高的晶体管密度和能效
- 支持先进低精度格式:首次原生支持FP4/FP6数据格式,这对AI推理任务至关重要,使其在这些关键精度下的峰值算力达到20 PFLOPS,大幅领先于B200的5 PFLOPS.
Google TPU v5e
- .TPU 其核心设计目标是以更高的性价比和能效,将大模型训练和推理能力带给更广泛的云客户
- 核心定位: 高性价比,通用型AI加速器,面向广泛的企业级AI训练与推理工作负载。
- 核心工艺: 基于台积电7nm 工艺制造。
- 片上互联 (ICI): 每芯片 400 GB/s 的双向带宽,用于芯片间高速互连。
- 系统形态: 以Pod形式提供:最小单元是256个芯片组成的 Pod,通过ICI互联,提供高达 100 PFLOPS 的聚合算力。
应用场景
- 专为通用性优化,TPU V5e 设计初衷是能够高效,经济的处理各种模型AI模型。
- 极高的能效比:仅90W的芯片功耗,结合聚合性能,使得TPU v5e在提供强大算力的同时,拥有非常出色的每瓦性能和总拥有成本优势,这对于需要大规模部署的云服务和企业用户至关重要。
Google TPU v5p
- 为大规模、前沿的AI模型训练提供顶级的峰值性能和可扩展性。
- TPU v5p是谷歌面向最苛刻AI工作负载的旗舰计算引擎
- 核心定位:极致性能,专为超大规模AI训练优化,高带宽内存每个芯片16GB, 片上互联带宽,每芯片480GB/s,一个Pod内所有芯片通过ICI全互联, 总带宽高达 276 TB/s,每芯片 90W,896个芯片组成一个Pod,提供 ~400 PFLOPS 聚合算力。
- TPU v5p 在单芯片算力和系统级互联上进行重点强化,其核心目标让数千个芯片能够高效协同,进行万亿级别大模型训练。
基于 InP 的 EML
- 基于 InP 的 EML(磷化铟电吸收调制激光器): 当前高速光模块(尤其是200G、400G及更高速率),中用于电信号转光信号的核心激光器芯片.
- 硅光(硅光子学): 用成熟的硅基半导体工艺(类似制造CPU的工艺)来制造光器件的技术。目标是把激光器、调制器、探测器等多种光元件集成到一块硅芯片上。能实现更高集成度、更低成本、更高能效。
- AI与超大规模数据中心。训练集群(如数万张H100/B200)和推理部署需要前所未有的超高带宽和低延迟互联,直接催生了对于800G、1.6T甚至更高速率光模块的海量需求
DR4 和 DR8 光模块
- DR4和DR8是目前数据中心内部短距互联(通常小于500米)最主流的两种800G光模块,它们都用于交换机与交换机、或交换机与计算服务器之间的高速连接,但设计逻辑、成本和适用场景有显著区别。
- DR4: 800G DR4, 4条发送通道,4条接收通道, 单通道速率100GB, 基于PAM4高阶调制,光纤使用量减半, 端口密度高, 系统侧布线更简洁, 成本与功耗相对更低
- DR8: 8条发送通道, 8条接收通道, 单通道速率50 Gbps (50G PAM4),光纤数量翻倍, 导致布线复杂度、功耗和综合成本增加。
Unusual Whales (美国金融数据分析平台)
SOCAMM 是小型压缩附加内存模块的缩写

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)