Agentic AI 实战教程:从零构建自主智能体系统_智能体搭建实战题目
低效提示“写一份市场报告。高效提示“你是一位拥有10年经验的市场研究分析师,擅长撰写半导体行业报告。请使用波特五力模型分析AI芯片市场竞争格局,包含具体数据和案例。角色提示模板你是\[角色名称\],拥有\[X年经验\],擅长\[核心技能\]。在\[领域/场景\]中,你以\[独特风格/方法\]著称。当处理\[任务类型\]时,你会优先考虑\[关键因素1\]、\[关键因素2\],并确保输出包含\[必要元
Agentic AI 正在重塑人工智能的边界——从被动响应指令的工具,进化为能独立规划、调用工具、反思改进的自主决策者。想象一个AI助手不仅能回答问题,还能主动分解复杂任务、调用计算器验证数据、查阅最新文献、甚至纠正自己的错误,全程无需人类干预。这不是科幻场景,而是当下Agentic AI(智能体AI)的真实能力。2024年,AutoGen、LangChain等框架的爆发式增长,让构建这类智能体系统从科研实验室走向了开发者的指尖。本教程将带你深入Agentic AI的技术内核,通过5个递进式实战案例、20+代码示例和8个可视化流程图,掌握构建自主智能体的核心原理与技能。
1. 理解Agentic AI:从工具到智能体的范式跃迁
传统AI系统本质是被动工具——给定明确指令,返回特定结果。当你询问"2024年诺贝尔物理学奖得主是谁",ChatGPT会直接回答;但当问题变为"撰写一份关于2024诺贝尔物理学奖成果的5000字研究报告,并包含3个专家观点和可视化数据"时,传统AI就会失效。Agentic AI(智能体AI) 的革命性在于:它能像人类一样主动规划任务、调用工具、整合信息、反思改进,最终完成需要多步骤协作的复杂目标。
1.1 智能体的核心特征
一个真正的AI智能体必须具备四大能力,缺一不可:
| 核心能力 | 定义 | 人类类比 | 典型实现技术 |
|---|---|---|---|
| 自主规划 | 将复杂任务分解为可执行的子目标,制定行动序列 | 项目经理拆分项目计划 | 思维链(Chain-of-Thought)、LLM规划能力 |
| 记忆系统 | 存储和检索历史信息,区分短期上下文与长期知识 | 大脑的工作记忆与长期记忆 | 向量数据库(Chroma/Pinecone)、上下文窗口 |
| 工具使用 | 调用外部API、程序或服务扩展能力(计算、搜索、控制设备等) | 使用计算器、搜索引擎、工具 | 函数调用(Function Calling)、API集成 |
| 反思修正 | 评估行动结果,识别错误并调整策略 | 复盘会议、自我纠错 | 反思提示(Reflection Prompt)、迭代优化 |
表1:AI智能体的四大核心能力对比
以学术写作智能体为例:它接到任务后,首先会规划步骤(确定主题→收集文献→分析数据→撰写初稿→修改润色);在收集文献阶段调用Google Scholar API(工具使用);将阅读过的论文摘要存储在向量数据库中(记忆系统);若发现某部分论述逻辑矛盾,会返回重新查找文献(反思修正)。整个过程无需人类介入,展现出类人的自主工作能力。
1.2 Agentic AI与传统AI的关键差异
为直观理解差异,我们通过"规划欧洲一周旅行"任务对比两类系统的行为模式:
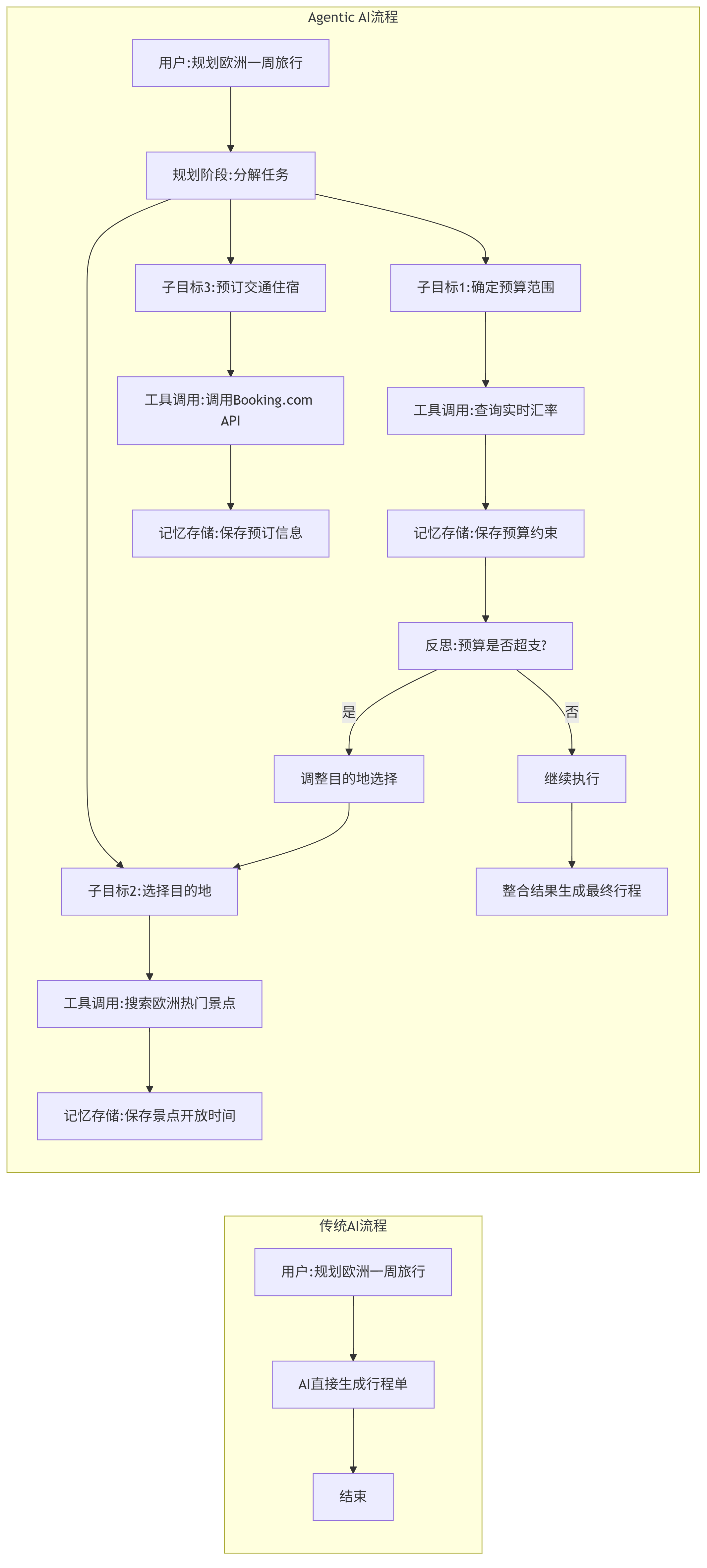
graph LR subgraph 传统AI流程 A[用户:规划欧洲一周旅行] --> B[AI直接生成行程单] B --> C[结束] end subgraph Agentic AI流程 D[用户:规划欧洲一周旅行] --> E[规划阶段:分解任务] E --> F["子目标1:确定预算范围"] E --> G["子目标2:选择目的地"] E --> H["子目标3:预订交通住宿"] F --> I[工具调用:查询实时汇率] G --> J[工具调用:搜索欧洲热门景点] H --> K[工具调用:调用Booking.com API] I --> L[记忆存储:保存预算约束] J --> M[记忆存储:保存景点开放时间] K --> N[记忆存储:保存预订信息] L --> O[反思:预算是否超支?] O -->|是| P[调整目的地选择] O -->|否| Q[继续执行] P --> G Q --> R[整合结果生成最终行程] end
图1:传统AI与Agentic AI处理复杂任务的流程对比
传统AI直接输出结果,无法处理模糊需求或动态变化(如用户突然说"预算减半");而Agentic AI通过动态规划-执行-反思循环,能适应需求变更、处理不确定性,并在过程中积累经验。这种自主性使其能胜任传统AI无法完成的开放式任务(如科研探索、创意设计、自主驾驶等)。
1.3 Agentic AI的应用场景与价值
Agentic AI已在多个领域展现出变革潜力:
-
知识工作自动化:法律智能体自动检索案例、起草合同;科研智能体设计实验、分析数据
-
个人数字助手:管理日程、自动回复邮件、预订服务,甚至帮你准备会议材料
-
工业智能控制:工厂中的维护智能体能自主检测设备异常、调用维修机器人、记录维修历史
-
教育个性化:根据学生学习数据生成定制化课程,调用编程环境让学生实时练习
根据Gartner预测,到2026年,75%的企业将部署至少一个AI智能体系统,取代25%的现有知识工作流程。掌握Agentic AI开发技能,已成为技术人员的重要竞争力。
2. 开发环境准备:构建智能体的技术栈与工具链
在动手构建智能体前,需要搭建完整的技术栈。本教程采用Python生态(AI开发的事实标准),配合主流框架和工具,确保代码可复现、易扩展。
2.1 核心技术栈选型
| 工具/框架 | 作用 | 选择理由 | 替代方案 |
|---|---|---|---|
| Python 3.10+ | 核心编程语言 | AI库生态最完善,语法简洁,适合快速开发 | - |
| LangChain | 智能体开发框架 | 提供规划、记忆、工具调用等模块化组件,支持多LLM集成 | AutoGen, CrewAI, LlamaIndex |
| OpenAI API | 提供LLM能力(GPT-4/GPT-3.5) | 函数调用能力成熟,生态支持好,适合快速原型开发 | Anthropic Claude, Google Gemini |
| Chroma | 本地向量数据库 | 轻量级,无需服务端,适合开发测试 | Pinecone(云端), FAISS(本地) |
| Jupyter Notebook | 交互式开发环境 | 支持代码分块执行,便于调试和演示 | VS Code + Python插件 |
表2:Agentic AI开发核心技术栈
为什么选择LangChain? 作为目前最流行的智能体开发框架,LangChain提供了"乐高式"的组件化工具集:Agent类封装智能体逻辑,Tool类定义工具接口,Memory类管理记忆系统,Chain类串联工作流。这种设计让开发者无需从零构建基础组件,可直接组合出复杂智能体。
2.2 环境搭建实战(10分钟入门)
步骤1:安装Python环境
推荐使用Anaconda管理Python环境(避免依赖冲突):
-
从Anaconda官网下载对应系统版本
-
安装时勾选"Add Anaconda to PATH"(Windows)或默认设置(Mac/Linux)
-
验证安装:打开终端输入conda --version,显示版本号即成功
步骤2:创建专用环境
# 创建名为agentic_ai的环境,指定Python 3.10 conda create -n agentic_ai python=3.10 -y # 激活环境 conda activate agentic_ai # Windows/Mac/Linux通用
步骤3:安装核心库
# 安装LangChain(智能体框架) pip install langchain==0.1.16 # 安装OpenAI SDK(调用GPT模型) pip install openai==1.30.1 # 安装Chroma(本地向量数据库) pip install chromadb==0.4.24 # 安装其他工具(JSON处理、环境变量管理等) pip install python-dotenv==1.0.0 pydantic==2.5.2
步骤4:配置OpenAI API密钥
-
访问OpenAI API平台注册账号并创建API密钥
-
在项目文件夹中创建.env文件,添加:
OPENAI_API_KEY="your_api_key_here" # 替换为实际API密钥
- 在Python中加载密钥:
from dotenv import load_dotenv import os load_dotenv() # 加载.env文件 openai_api_key = os.getenv("OPENAI_API_KEY") if not openai_api_key: raise ValueError("请设置OPENAI_API_KEY环境变量")
步骤5:验证开发环境
启动Jupyter Notebook,运行测试代码:
from langchain.llms import OpenAI from langchain.chains import LLMChain from langchain.prompts import PromptTemplate # 初始化LLM llm = OpenAI(api_key=openai_api_key, temperature=0.7) # 创建简单对话链 prompt = PromptTemplate(input_variables=["question"], template="回答问题: {question}") chain = LLMChain(llm=llm, prompt=prompt) # 测试 print(chain.run(question="什么是Agentic AI?"))
若输出包含对Agentic AI的解释,说明环境配置成功!
2. 智能体核心组件深度解析与实战
2.1 规划模块:让智能体学会"拆解任务"
规划是智能体的"大脑指挥官",负责将模糊目标转化为清晰行动步骤。例如,当接到"分析2024年Q1全球智能手机市场份额"任务时,规划模块会生成:
-
确定数据来源(IDC/Canalys报告)
-
收集各品牌销量数据
-
计算市场份额百分比
-
对比2023年Q4变化
-
生成趋势图表
2.1.1 规划能力的技术实现
目前主流的规划技术有三种,各有适用场景:
| 规划方法 | 原理 | 优势 | 局限 | 适用场景 | |------------------------|-------------------------------|---------------------------------------|---------------------------------------| | 思维链提示 | 通过自然语言提示引导LLM逐步思考 | 无需代码修改,灵活适应不同任务 | 复杂任务规划准确性低 | 简单任务、创意类规划 | | 基于LLM的规划器 | 专用提示模板+LLM生成结构化计划 | 输出格式可控,便于下游执行 | 依赖提示质量,可能生成不可行步骤 | 中等复杂度任务、流程固定场景 | | 外部规划算法 | 集成经典规划算法(如STRIPS) | 保证计划可行性,支持复杂约束 | 开发复杂度高,灵活性差 | 工业控制、机器人路径规划等高可靠性场景 |
表3:三种主流规划技术对比
2.1.2 实战:用LangChain实现任务分解
以下代码演示如何构建一个旅游规划智能体的规划模块,将"日本东京5日游"分解为详细子任务:
from langchain.chat_models import ChatOpenAI from langchain.prompts.chat import ( ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate, ) from langchain.chains import LLMChain # 初始化LLM(使用GPT-4获得更好的规划能力) chat = ChatOpenAI(model_name="gpt-4", temperature=0.7, api_key=openai_api_key) # 系统提示:定义规划器角色和输出格式 system_prompt = """ 你是一个专业旅游规划师,擅长将复杂旅行需求分解为可执行的子任务。 请遵循以下步骤规划: 1. 分析用户需求的关键要素(目的地、时长、预算、兴趣偏好) 2. 将旅行计划分解为5-8个核心子任务,按时间顺序排列 3. 每个子任务需包含:任务名称、主要行动、预期成果 输出格式要求(使用Markdown列表): - 任务1:[任务名称] 行动:[具体要做什么] 成果:[完成后获得什么] """ system_message = SystemMessagePromptTemplate.from_template(system_prompt) # 用户输入模板 human_message = HumanMessagePromptTemplate.from_template("{travel_requirement}") chat_prompt = ChatPromptTemplate.from_messages([system_message, human_message]) # 创建规划链 planning_chain = LLMChain(llm=chat, prompt=chat_prompt) # 测试:分解"东京5日游"任务 result = planning_chain.run(travel_requirement="规划东京5日游,预算中等,喜欢美食和历史景点") print(result)
输出结果示例:
\- 任务1:确定行程框架
行动:分析东京主要区域分布,根据5天时间分配游览区域,平衡景点密度与交通时间
成果:东京5日游区域分配表(如:浅草寺区域1天、涩谷新宿区域1天等)
- 任务2:景点筛选与优先级排序
行动:根据"历史景点"偏好筛选浅草寺、明治神宫等景点;根据"美食"偏好收集筑地市场、拉面街等信息;按吸引力和开放时间排序
成果:每日景点清单(含开放时间、门票价格、预计游览时长)
- 任务3:交通方案规划
行动:研究东京地铁/公交系统,确定是否购买JR Pass或Suica卡,规划每日景点间交通路线
成果:交通卡购买建议、每日详细交通路线图(含步行距离、预计时间)
...(后续任务省略)
2.1.3 可视化规划流程
智能体的规划过程本质是"需求→理解→分解→结构化输出"的转换,其内部逻辑可用以下流程图表示:
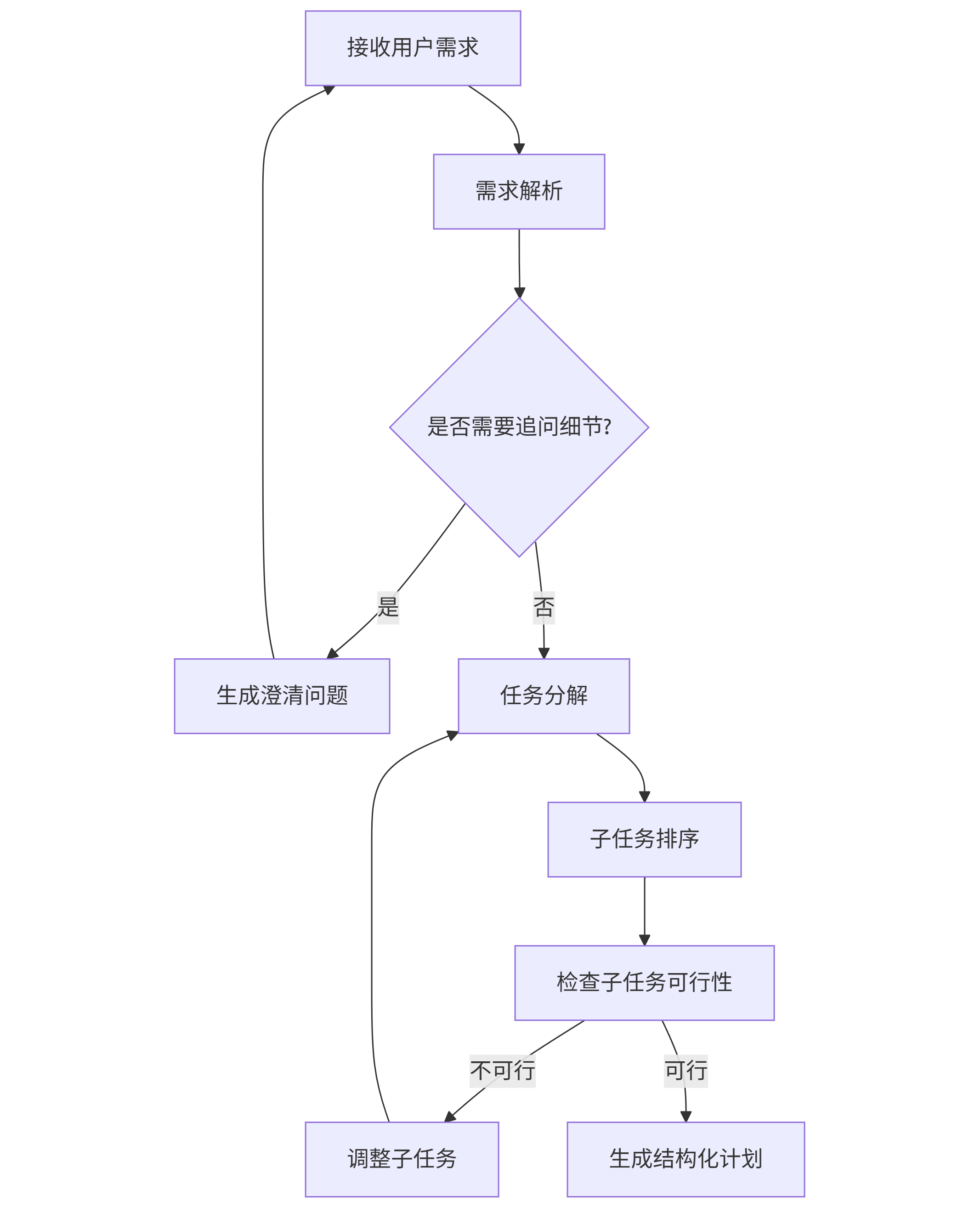
graph TD A[接收用户需求] --> B[需求解析] B --> C{是否需要追问细节?} C -->|是| D[生成澄清问题] C -->|否| E[任务分解] E --> F[子任务排序] F --> G[检查子任务可行性] G -->|不可行| H[调整子任务] G -->|可行| I[生成结构化计划] D --> A H --> E
图2:智能体任务规划流程图
关键节点说明:
-
需求解析:提取核心要素(如旅行规划中的目的地、时间、预算)
-
可行性检查:验证子任务是否可执行(如"当天往返富士山"是否在时间允许范围内)
-
动态调整:若发现子任务冲突(如两个景点距离过远无法同日参观),返回重新规划
2.2 记忆系统:智能体的"大脑存储"
人类决策严重依赖记忆——医生根据患者病史诊断,老师根据学生过往表现调整教学。同样,AI智能体需要记忆系统存储和检索信息,支持长期知识积累和上下文感知决策。
2.2.1 记忆系统的核心类型
智能体记忆可按存储周期和功能分为四类,共同构成完整记忆体系:
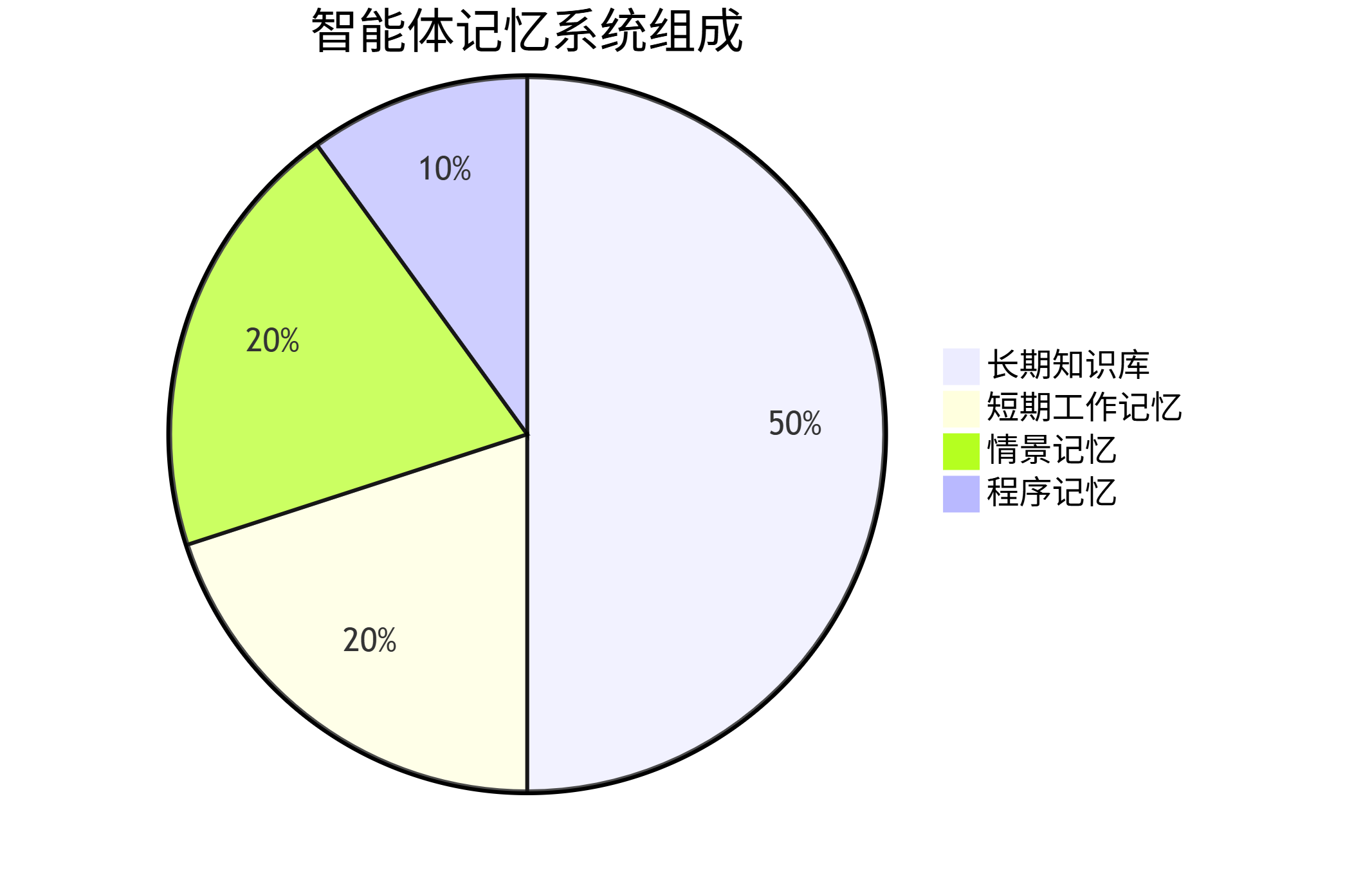
pie title 智能体记忆系统组成 "短期工作记忆" : 20 "长期知识库" : 50 "情景记忆" : 20 "程序记忆" : 10
图3:智能体记忆系统组成比例
-
短期工作记忆:存储当前对话上下文(如用户最近的5条消息),通常使用LLM的上下文窗口实现,容量有限(GPT-4约8k-128k tokens)
-
长期知识库:存储领域知识、事实信息(如公司产品手册、法律条文),需通过向量数据库持久化存储
-
情景记忆:记录智能体的历史行动和结果(如"2024-10-01调用天气API失败"),支持反思学习
-
程序记忆:存储操作流程知识(如"调用计算器工具的参数格式"),通常编码为工具定义或提示模板
2.2.2 向量数据库:长期记忆的存储引擎
长期知识库的实现依赖向量数据库——将文本转化为高维向量(Embedding),通过向量相似度搜索快速召回相关信息。其核心优势在于:
-
高效检索:相似内容的向量距离更近,可快速找到相关知识
-
语义理解:基于内容含义而非关键词匹配(如"汽车"和"交通工具"会被判定为相关)
-
无限扩展:突破LLM上下文窗口限制,理论上可存储无限知识
2.2.3 实战:构建带记忆的问答智能体
以下案例实现一个产品手册问答智能体,能记住并检索产品信息(以"智能手表用户手册"为例):
from langchain.document_loaders import TextLoader # 加载文本文件 from langchain.embeddings.openai import OpenAIEmbeddings # 生成向量 from langchain.vectorstores import Chroma # 向量数据库 from langchain.chains import RetrievalQA # 检索问答链 from langchain.text_splitter import CharacterTextSplitter # 文本分块 # 步骤1:准备知识库(智能手表用户手册文本) # 创建示例产品手册内容 with open("smartwatch_manual.txt", "w", encoding="utf-8") as f: f.write("""智能手表使用手册 1. 充电方法:使用配套磁吸充电器,充电接口在表盘背面,充满需2小时。 2. 防水等级:IP68,支持50米深防水,可用于游泳但不适合潜水。 3. 健康监测功能:心率监测(实时/每5分钟)、血氧检测(需手动开启)、睡眠追踪(自动识别睡眠状态)。 4. 电池续航:普通模式下约3天,省电模式下可达7天。 """) # 步骤2:加载并处理文档 loader = TextLoader("smartwatch_manual.txt", encoding="utf-8") documents = loader.load() # 文本分块(长文本需拆分才能有效检索,块大小500字符,重叠50字符) text_splitter = CharacterTextSplitter( chunk_size=500, chunk_overlap=50, separator="\n" ) texts = text_splitter.split_documents(documents) # 步骤3:创建向量数据库 embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key) # 持久化存储到本地文件夹"smartwatch_db" db = Chroma.from_documents( texts, embeddings, persist_directory="./smartwatch_db" ) db.persist() # 保存到磁盘 # 步骤4:构建带记忆的问答链 qa = RetrievalQA.from_chain_type( llm=ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, api_key=openai_api_key), chain_type="stuff", # 将检索到的文档填入提示 retriever=db.as_retriever(search_kwargs={"k": 1}), # 检索最相关的1个文档块 ) # 测试:提问产品问题 query = "这个智能手表防水吗?可以戴着潜水吗?" result = qa.run(query) print(f"问题:{query}\n回答:{result}")
输出结果:
问题:这个智能手表防水吗?可以戴着潜水吗?
回答:智能手表的防水等级为IP68,支持50米深防水,可用于游泳但不适合潜水。
关键技术点:
-
文本分块:长文档需拆分为小块(500-1000字符),避免向量表示过于模糊
-
向量检索:search_kwargs={“k”: 1}表示只返回最相关的1个文档块,减少噪音
-
持久化存储:persist_directory参数将向量数据库保存到本地,下次运行可直接加载
2.3 工具使用:让智能体"动手做事"
如果说规划和记忆是智能体的"大脑",那么工具使用就是它的"双手"。现实世界中,90%以上的实用任务都需要与外部系统交互:计算复杂数学题需调用计算器,获取实时天气需调用API,控制智能家居需发送指令。函数调用(Function Calling) 技术的出现,使LLM能像程序员一样调用工具,极大扩展了智能体的能力边界。
2.3.1 函数调用的工作原理
函数调用的核心流程可概括为"识别需求→选择工具→参数填充→执行调用→处理结果"五步:
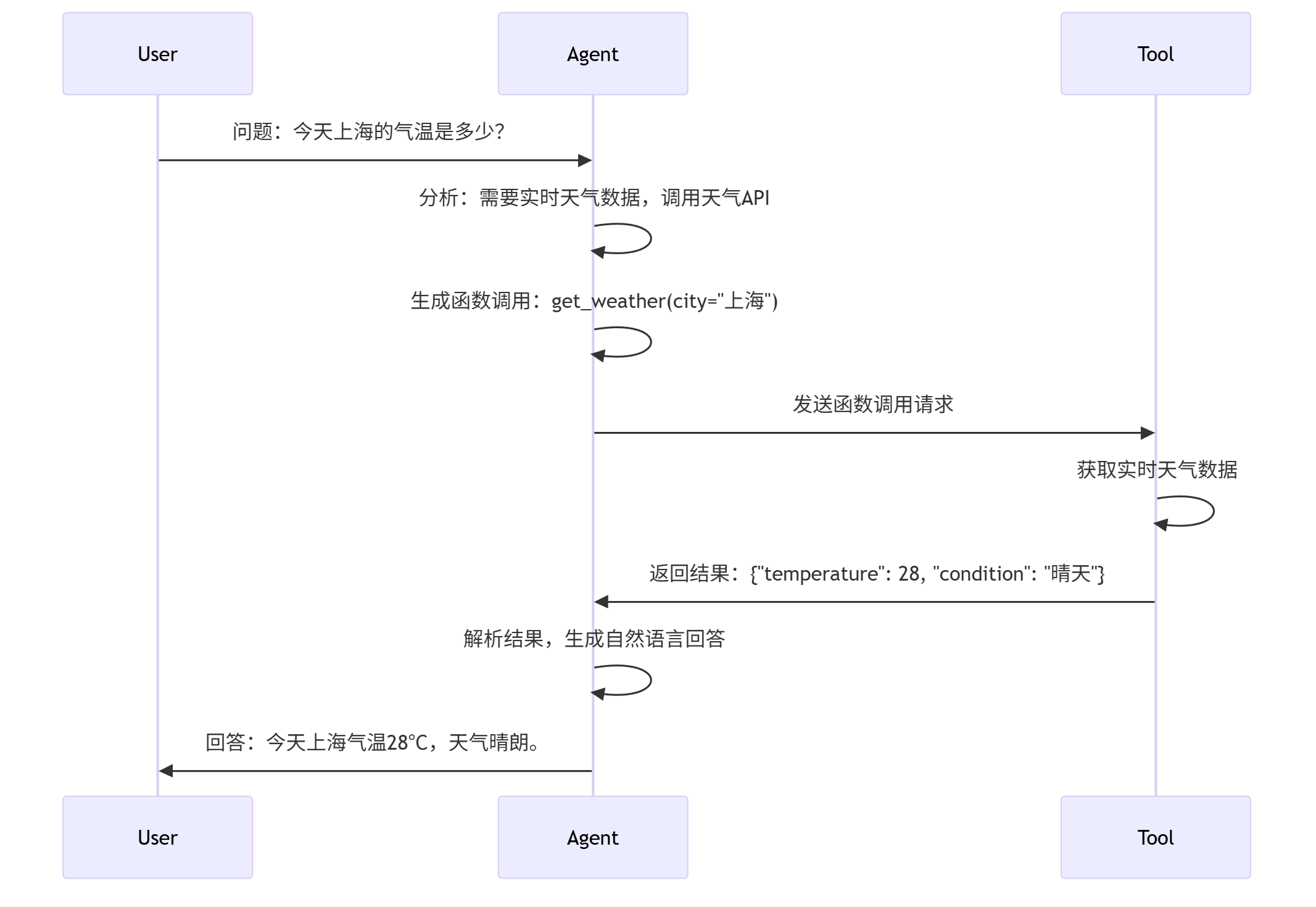
sequenceDiagram participant User participant Agent participant Tool User->>Agent: 问题:今天上海的气温是多少? Agent->>Agent: 分析:需要实时天气数据,调用天气API Agent->>Agent: 生成函数调用:get_weather(city="上海") Agent->>Tool: 发送函数调用请求 Tool->>Tool: 获取实时天气数据 Tool->>Agent: 返回结果:{"temperature": 28, "condition": "晴天"} Agent->>Agent: 解析结果,生成自然语言回答 Agent->>User: 回答:今天上海气温28℃,天气晴朗。
图4:函数调用工作流程时序图
关键技术挑战在于:如何让LLM准确判断何时需要调用工具、调用哪个工具、如何填充参数。OpenAI在2023年6月推出的function calling API,通过结构化提示和JSON输出解决了这一问题。
2.3.2 实战:构建带计算器的数学智能体
以下案例实现一个数学解题智能体,当遇到无法心算的复杂计算时,自动调用计算器工具:
from langchain.agents import initialize_agent, Tool from langchain.agents import AgentType from langchain.tools import BaseTool from langchain.llms import OpenAI import math # 步骤1:定义工具函数(计算器) def calculate(expression: str) -> str: """ 计算数学表达式的结果。 参数: expression: 字符串形式的数学表达式,支持+、-、*、/、^(幂运算)、sqrt(开方)等 返回: 计算结果字符串 """ try: # 替换^为**(Python幂运算符号) expression = expression.replace("^", "**") # 使用eval计算表达式,限制允许的函数和变量 allowed_globals = {"__builtins__": None, "math": math} result = eval(expression, allowed_globals) return f"计算结果: {result}" except Exception as e: return f"计算错误: {str(e)}" # 步骤2:将函数包装为LangChain工具 tools = [ Tool( name="Calculator", # 工具名称 func=calculate, # 关联函数 # 工具描述(关键!LLM通过此描述决定是否调用该工具) description="当需要进行数学计算(如加减乘除、幂运算、开方等)时使用,输入应为数学表达式字符串" ) ] # 步骤3:初始化智能体 llm = OpenAI( temperature=0, # 降低随机性,确保计算准确性 model_name="text-davinci-003", api_key=openai_api_key ) # 使用ZERO_SHOT_REACT_DESCRIPTION类型智能体 agent = initialize_agent( tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True # 输出思考过程 ) # 测试:复杂数学问题 print(agent.run("问题:一个球体的半径是5厘米,它的表面积是多少?(球体表面积公式:4πr²)"))
输出结果(包含智能体思考过程):
\> Entering new AgentExecutor chain...
I need to calculate the surface area of a sphere with radius 5 cm. The formula is 4πr².
First, I should compute r squared. r is 5, so 5 squared is 25. Then multiply by 4 and π.
I need to use the calculator for this. The expression should be 4 \* math.pi \* (5 \*\*2)
Action: Calculator
Action Input: 4 \* math.pi \* (5\*\* 2)
Observation: 计算结果: 314.1592653589793
Thought: I now know the surface area is approximately 314.16 square centimeters.
Final Answer: 该球体的表面积约为314.16平方厘米。
> Finished chain.
该球体的表面积约为314.16平方厘米。
成功关键:
-
工具描述:清晰说明工具用途和输入格式,帮助LLM判断是否调用
-
思维链输出:verbose=True显示智能体的"思考过程",便于调试
-
参数控制:temperature=0确保计算逻辑稳定,避免随机错误
2.3.3 工具选择的决策逻辑
智能体如何在多个工具中选择最合适的?这取决于两个因素:工具描述匹配度和任务需求紧迫性。以下是一个简化的工具选择模型:
def select_tool(query: str, tools: list) -> str: """简化的工具选择逻辑示例""" # 1. 关键词匹配:检查查询是否包含工具相关关键词 tool_keywords = { "Calculator": ["计算", "数学", "公式", "数值", "加", "减", "乘", "除"], "WeatherAPI": ["天气", "温度", "预报", "下雨", "晴天"], "SearchEngine": ["最新", "2024", "新闻", "事件", "数据"] } # 2. 计算每个工具的匹配分数 scores = {} for tool in tools: tool_name = tool.name keywords = tool_keywords.get(tool_name, []) score = sum(1 for kw in keywords if kw in query) scores[tool_name] = score # 3. 选择分数最高的工具 return max(scores, key=scores.get) if scores else None
实际应用中,这一决策由LLM通过分析工具描述和当前任务自动完成,但理解其底层逻辑有助于设计更有效的工具描述。
2.4 反思修正:让智能体"从错误中学习"
即使规划周密、工具强大,智能体仍会犯错:调用工具时参数错误、误解用户意图、遗漏关键信息。反思修正能力使智能体能够"自我检查"并改进,而无需人类干预。
2.4.1 反思机制的实现方式
目前主流的反思实现有三种技术路径:
1.** 结果对比反思 :将实际结果与预期结果对比,识别差异
2. 过程回溯反思 :重新检查每一步决策,找出错误节点
3. 外部反馈反思 **:结合用户或环境反馈调整策略
其中,过程回溯反思在代码实现上最为简单有效,其核心思想是:让智能体"重放"思考过程,判断是否存在逻辑漏洞。
2.4.2 实战:带反思能力的代码调试智能体
以下案例构建一个Python代码调试智能体,它能在代码运行出错后,自动分析错误信息并修正代码:
from langchain import LLMChain, PromptTemplate from langchain.chat_models import ChatOpenAI # 步骤1:定义反思提示模板 REFLECTION_PROMPT = """ 你是一位专业Python开发者,负责调试以下代码。请遵循以下步骤: 1. 分析错误信息,确定错误类型和位置 2. 解释错误原因(用通俗语言) 3. 提出具体修改方案(提供完整修正代码) 代码: {code} 错误信息: {error_message} 反思输出格式: 错误类型: [例如:语法错误/逻辑错误/导入错误] 错误原因: [详细解释] 修正代码: [完整的修正后代码] """ # 步骤2:创建反思链 reflection_prompt = PromptTemplate( input_variables=["code", "error_message"], template=REFLECTION_PROMPT, ) reflection_chain = LLMChain( llm=ChatOpenAI(model_name="gpt-4", temperature=0, api_key=openai_api_key), prompt=reflection_prompt, ) # 步骤3:构建调试智能体主流程 def debug_agent(code: str) -> str: try: # 尝试执行代码 exec(code, globals()) return "代码执行成功!" except Exception as e: # 获取错误信息 error_msg = str(e) print(f"执行错误: {error_msg}\n开始反思修正...") # 调用反思链生成修正方案 reflection_result = reflection_chain.run( code=code, error_message=error_msg ) # 解析修正代码(从反思结果中提取"修正代码:"后的内容) if "修正代码:" in reflection_result: corrected_code = reflection_result.split("修正代码:")[1].strip() print(f"修正方案:\n{reflection_result}\n") print(f"尝试执行修正后代码...") # 递归调用:测试修正后的代码 return debug_agent(corrected_code) else: return f"无法修正错误: {reflection_result}" # 测试:包含错误的Python代码 buggy_code = """ # 计算斐波那契数列第n项 def fibonacci(n): if n <= 0: return "输入必须为正整数" elif n == 1: return 0 elif n == 2: return 1 else: return fibonacci(n-1) + fibonacci(n-2) # 测试:计算第10项 print(fibonacci(10)) """ # 运行调试智能体 result = debug_agent(buggy_code) print(result) ```** 输出结果**(简化版):
执行错误: 超过最大递归深度 开始反思修正… 修正方案: 错误类型: 逻辑错误 错误原因: 斐波那契数列定义错误。常见定义中fibonacci(1)=1, fibonacci(2)=1, fibonacci(3)=2… 而当前代码fibonacci(1)=0, fibonacci(2)=1,且未设置递归终止条件,导致计算第10项时递归过深。 修正代码:
计算斐波那契数列第n项
def fibonacci(n): if not isinstance(n, int) or n <= 0: return “输入必须为正整数” # 设置递归终止条件 elif n == 1 or n == 2: return 1 else: return fibonacci(n-1) + fibonacci(n-2)
测试:计算第10项
print(fibonacci(10))
尝试执行修正后代码… 55 代码执行成功!
\#### 2.4.3 反思能力的关键要素
成功的反思修正依赖三个要素:
1.\*\* 错误信息完整性 \*\*:越详细的错误日志(如Python的Traceback),反思越准确
2.\*\* 领域知识 \*\*:针对特定任务的专业反思提示(如代码调试需编程知识)
3.\*\* 迭代次数控制\*\*:避免无限修正循环(通常设置3-5次迭代上限)
## 3. 实战案例:构建多智能体协作系统
单个智能体能力有限,正如人类社会通过分工协作解决复杂问题,\*\*多智能体系统\*\*将不同功能的智能体组合,各司其职、协同工作,能完成更具挑战性的任务。本节通过"市场调研报告生成"案例,展示如何构建包含3个专业智能体的协作系统。
### 3.1 多智能体系统的架构设计
一个典型的多智能体系统包含\*\*智能体角色\*\*、\*\*通信机制\*\*和\*\*协调策略\*\*三大要素:
#### 3.1.1 智能体角色划分
为生成高质量市场调研报告,我们设计三个专业智能体:
| 智能体角色 | 核心职责 | 所需工具/能力 | 输出产物 |
|----------------|-------------------------------------------|---------------------------------------|-----------------------------------|
|\*\* 研究智能体 \*\*| 收集行业数据、文献和报告 | 搜索引擎API、学术数据库访问 | 数据摘要、关键趋势、专家观点 |
|\*\* 分析智能体 \*\*| 解读数据、识别模式和洞察 | 统计分析工具、图表生成器 | 数据分析报告、可视化图表、结论 |
|\*\* 写作智能体 \*\*| 将分析结果转化为结构化报告 | 文档格式化工具、Markdown渲染器 | 排版后的最终报告 |
\*表4:市场调研多智能体系统角色分工\*
#### 3.1.2 通信机制
智能体间需传递信息,常用通信方式有:
-\*\* 共享内存 \*\*:所有智能体访问同一个数据库或变量(简单但不灵活)
-\*\* 消息队列 \*\*:通过结构化消息传递数据(如JSON格式),支持异步通信
-\*\* 直接调用\*\*:一个智能体直接调用另一个智能体的方法(适合Python开发)
本案例采用\*\*直接调用+共享结果字典\*\*的混合方式,平衡简单性和灵活性。
#### 3.1.3 协调策略
多智能体协调策略主要有三种:
\`\`\`mermaid
graph TD
A\[用户需求\] --> B\[主智能体分配任务\]
B --> C\[研究智能体\]
B --> D\[分析智能体\]
B --> E\[写作智能体\]
C --> F\[完成研究\]
D --> G\[完成分析\]
E --> H\[完成写作\]
F --> D
G --> E
H --> I\[输出最终报告\]
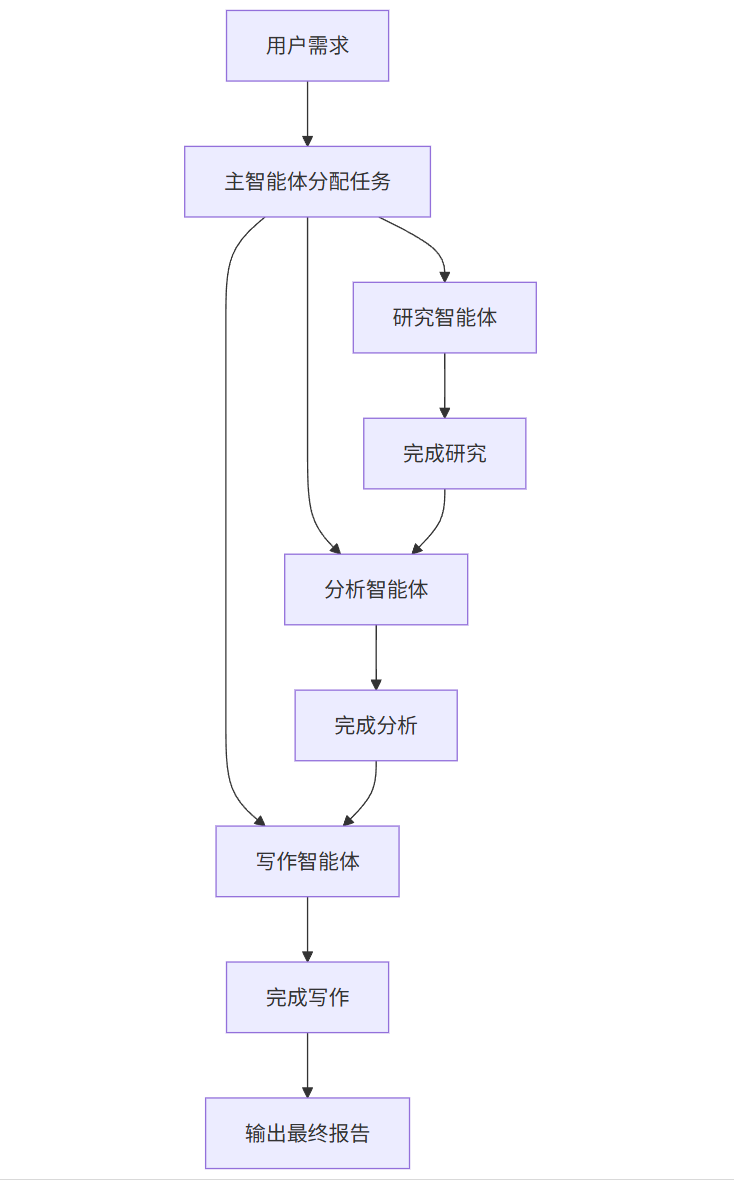
图5:顺序执行协调策略流程图
顺序执行策略:研究→分析→写作依次执行,前一智能体输出作为后一智能体输入,适合流程固定的任务。
3.2 多智能体系统实战代码
以下代码实现完整的市场调研多智能体系统,以"2024年全球AI芯片市场"为主题生成报告:
from langchain.agents import initialize_agent, Tool, AgentType from langchain.chat_models import ChatOpenAI from langchain.chains import LLMChain from langchain.prompts import PromptTemplate import json import time # 全局共享结果存储 shared_results = { "research_data": "", # 研究智能体输出 "analysis_result": "", # 分析智能体输出 "final_report": "" # 写作智能体输出 } # ---------------------- 1. 研究智能体 ---------------------- class ResearchAgent: def __init__(self, api_key): # 初始化研究工具(此处简化为模拟搜索,实际项目需集成真实API) self.tools = [ Tool( name="MarketSearch", func=self.mock_market_search, description="搜索市场规模、增长率、主要厂商份额等数据" ), Tool( name="TrendAnalysis", func=self.mock_trend_analysis, description="分析行业技术趋势、政策影响、消费者偏好变化" ) ] # 初始化研究智能体 self.agent = initialize_agent( self.tools, ChatOpenAI(model_name="gpt-4", temperature=0.5, api_key=api_key), agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True ) # 研究提示模板 self.research_prompt = """ 任务:收集关于"{topic}"的市场研究数据,包括: 1. 2023-2024年市场规模及增长率(亿美元) 2. 主要厂商(至少5家)及市场份额 3. 关键技术趋势(至少3个) 4. 主要应用领域及占比 以结构化JSON格式输出,包含上述四个key。 """ def mock_market_search(self, query: str) -> str: """模拟市场数据搜索工具(实际项目替换为Google Scholar/Statista API)""" # 模拟API调用延迟 time.sleep(1) # 预定义模拟数据 mock_data = { "2024全球AI芯片市场规模": "约890亿美元,年增长率35%", "AI芯片主要厂商": "NVIDIA(58%), AMD(12%), Intel(8%), 华为海思(5%), 寒武纪(3%), 其他(14%)", "AI芯片应用领域": "数据中心(62%), 边缘设备(23%), 汽车(8%), 其他(7%)" } return mock_data.get(query, f"未找到'{query}'相关数据") def mock_trend_analysis(self, query: str) -> str: """模拟趋势分析工具""" time.sleep(1) mock_trends = { "AI芯片技术趋势": """1. 3D堆叠技术:通过垂直堆叠芯片提升算力密度,如NVIDIA H100的3D V-Cache 2. 专用架构:针对LLM优化的架构,如AMD MI300的CDNA 3 3. 能效提升:采用4nm/3nm工艺,降低每TOPS能耗""" } return mock_trends.get(query, f"未找到'{query}'相关趋势") def run(self, topic: str) -> dict: """执行研究任务""" print(f"\n===== 研究智能体开始工作:{topic} =====") research_query = self.research_prompt.format(topic=topic) result = self.agent.run(research_query) # 解析JSON结果(简化处理,实际需添加错误处理) try: parsed_result = json.loads(result) shared_results["research_data"] = parsed_result return parsed_result except: return {"error": "研究结果解析失败", "raw_result": result} # ---------------------- 2. 分析智能体 ---------------------- class AnalysisAgent: def __init__(self, api_key): self.llm = ChatOpenAI(model_name="gpt-4", temperature=0.3, api_key=api_key) self.analysis_prompt = PromptTemplate( input_variables=["research_data"], template=""" 基于以下市场研究数据,进行深入分析: {research_data} 分析要求: 1. 识别市场增长驱动因素(至少3个) 2. 评估主要厂商竞争格局(优势/劣势) 3. 预测未来2年发展趋势 4. 指出潜在风险和挑战 输出格式:分点论述,每部分标题加粗。 """ ) self.analysis_chain = LLMChain(llm=self.llm, prompt=self.analysis_prompt) def run(self) -> str: """执行分析任务""" print("\n===== 分析智能体开始工作 =====") if not shared_results["research_data"]: return "错误:没有研究数据可供分析" result = self.analysis_chain.run(research_data=shared_results["research_data"]) shared_results["analysis_result"] = result return result # ---------------------- 3. 写作智能体 ---------------------- class WritingAgent: def __init__(self, api_key): self.llm = ChatOpenAI(model_name="gpt-4", temperature=0.4, api_key=api_key) self.writing_prompt = PromptTemplate( input_variables=["topic", "research_data", "analysis_result"], template=""" 根据以下研究数据和分析结果,撰写一份专业市场调研报告: 主题:{topic} 研究数据:{research_data} 分析结果:{analysis_result} 报告结构要求: 1. 执行摘要(200字) 2. 市场概况(规模、增长) 3. 竞争格局(主要厂商分析) 4. 技术趋势(最新发展) 5. 挑战与风险 6. 结论与建议 格式要求:使用Markdown,包含标题、小标题、项目符号,适当使用粗体突出关键点。 """ ) self.writing_chain = LLMChain(llm=self.llm, prompt=self.writing_prompt) def run(self, topic: str) -> str: """执行写作任务""" print("\n===== 写作智能体开始工作 =====") if not shared_results["analysis_result"]: return "错误:没有分析结果可供写作" result = self.writing_chain.run( topic=topic, research_data=shared_results["research_data"], analysis_result=shared_results["analysis_result"] ) shared_results["final_report"] = result return result # ---------------------- 4. 系统集成 ---------------------- if __name__ == "__main__": # 初始化三个智能体 research_agent = ResearchAgent(openai_api_key) analysis_agent = AnalysisAgent(openai_api_key) writing_agent = WritingAgent(openai_api_key) # 执行多智能体协作流程 topic = "2024年全球AI芯片市场" research_agent.run(topic) # 研究阶段 analysis_agent.run() # 分析阶段 final_report = writing_agent.run(topic) # 写作阶段 # 输出最终报告 print("\n===== 最终市场调研报告 =====") print(final_report)
3.3 系统输出结果示例(节选)
# 2024年全球AI芯片市场调研报告 ## 1. 执行摘要 2024年全球AI芯片市场规模预计达890亿美元,年增长率35%,延续高速增长态势。NVIDIA以58%的市场份额占据主导地位,AMD和Intel通过架构创新快速追赶。技术层面,3D堆叠、专用LLM优化架构和能效提升成为三大趋势。数据中心仍是主要应用领域,占比62%,但边缘设备和汽车场景增长迅速。本报告分析了市场格局、技术趋势及主要挑战,为行业参与者提供战略参考。 ## 2. 市场概况 - **规模与增长**:890亿美元(2024年),较2023年增长35% - **驱动因素**:大语言模型训练需求、生成式AI应用普及、数据中心建设加速 - **区域分布**:北美(42%)、亚太(35%)、欧洲(18%)、其他(5%) ## 3. 竞争格局 **主要厂商分析**: - **NVIDIA**:优势在于完整软硬件生态(CUDA+Hopper架构),H100芯片占据高端市场;劣势是价格昂贵,面临供应链限制 - **AMD**:通过MI300系列和CDNA 3架构快速增长,性价比优势明显,但软件生态仍待完善 - **华为海思/寒武纪**:在国内政策支持下份额提升,但全球化面临挑战 ...(后续章节省略)
4. 智能体提示工程:提升性能的关键技巧
即使使用相同的框架和工具,不同提示设计会导致智能体性能天差地别。提示工程(Prompt Engineering) 是提升智能体能力的"软实力",本节总结6个核心技巧并提供模板。
4.1 角色定义提示
为智能体分配明确角色,激活LLM的领域专家能力:
低效提示:
“写一份市场报告。”
高效提示:
“你是一位拥有10年经验的市场研究分析师,擅长撰写半导体行业报告。请使用波特五力模型分析AI芯片市场竞争格局,包含具体数据和案例。”
角色提示模板:
你是\[角色名称\],拥有\[X年经验\],擅长\[核心技能\]。在\[领域/场景\]中,你以\[独特风格/方法\]著称。
当处理\[任务类型\]时,你会优先考虑\[关键因素1\]、\[关键因素2\],并确保输出包含\[必要元素\]。
4.2 格式约束提示
指定输出格式,确保智能体生成机器可解析的结构化结果:
示例:
“以JSON格式输出分析结果,包含以下键:topic (字符串), key_findings (数组), recommendations (数组)。每个recommendation包含’action’和’priority’字段。”
常见格式类型:
-
JSON/CSV(便于数据处理)
-
Markdown(文档生成)
-
函数调用格式(工具调用)
4.3 思维链提示
引导智能体逐步思考,提高复杂任务准确率:
数学问题思维链提示:
"解决这个数学问题:一个商店有3排货架,每排有8盒巧克力,每盒12块。如果每块巧克力售价2元,全部售出能收入多少元? 请按照以下步骤思考:
-
计算总盒数:货架排数 × 每排盒数
-
计算总块数:总盒数 × 每盒块数
-
计算总收入:总块数 × 单价 最后给出答案。"
4.4 反思提示
引导智能体自我检查,修正错误:
反思提示模板:
"你刚刚给出了以下回答:{agent_answer} 请从以下角度检查是否需要改进:
-
事实准确性:是否有错误信息或过时数据?
-
逻辑一致性:论证过程是否存在矛盾?
-
完整性:是否遗漏关键信息或步骤?
-
清晰度:表达是否简洁易懂? 如果发现问题,请修改你的回答并说明改进之处。"
4.5 工具调用提示
明确说明何时以及如何调用工具:
工具调用提示示例:
"当遇到以下情况时,必须使用工具:
-
需要实时数据(如天气、新闻、股价)
-
涉及复杂计算(如数学公式、统计分析)
-
需要访问特定知识(如公司文档、内部数据库)
调用格式:<|FunctionCallBegin|>[{“name”:“工具名”,“parameters”:{“参数名”:“值”}}]<|FunctionCallEnd|> 确保参数格式正确,避免拼写错误。"
4.6 负面示例提示
通过"反面教材"明确智能体不应做什么:
负面示例提示:
"避免以下错误:
-
不要编造数据,未知信息明确标注’数据不可用’
-
不要使用过于技术化的术语,假设读者为非专业人士
-
不要超过500字,保持简洁"
5. 智能体评估与优化
构建智能体后,如何判断其性能优劣?科学评估和系统性优化是将原型转化为产品的关键步骤。
5.1 核心评估指标
智能体评估需覆盖功能性和非功能性两大维度:
| 维度 | 关键指标 | 评估方法 |
|---|---|---|
| 功能性 | 任务成功率 | 100个测试用例中成功完成的比例 |
| 工具调用准确率 | 正确选择工具和参数的调用占比 | |
| 错误恢复能力 | 遇到错误后成功修正并完成任务的比例 | |
| 非功能性 | 响应时间 | 平均任务完成时间 |
| 资源消耗 | 平均Token使用量、API调用成本 | |
| 鲁棒性 | 异常输入(如乱码、超长文本)下的稳定性 |
表5:智能体核心评估指标
5.2 优化策略
根据评估结果,可从以下方面优化智能体:
-
提示优化:基于错误案例改进提示模板
-
工具扩展:添加更多专用工具处理薄弱任务
-
记忆增强:优化向量数据库检索策略,增加记忆容量
-
参数调优:调整LLM的temperature(0.0-1.0)、max_tokens等参数
6. 未来展望:Agentic AI的下一个前沿
随着技术演进,Agentic AI将向三个方向突破:
6.1 多模态智能体
当前智能体主要处理文本,未来将整合视觉、听觉、触觉等多模态能力。想象一个家庭助手智能体:通过摄像头"看到"快递盒,通过语音"询问"是否拆开,通过机械臂"拿起"并打开包装。
6.2 自主进化智能体
通过强化学习和持续学习,智能体将能自主改进策略,无需人工更新代码。例如,销售智能体通过分析成交/未成交记录,自动优化沟通话术。
6.3 群体智能体系统
数百万智能体组成的"智能社会",通过分工协作解决全球性问题:气候模拟、疾病防控、城市规划等。每个智能体专精一个子领域,通过区块链等技术实现信任与协作。
结语:智能体时代的人机协作新范式
从被动工具到自主智能体,AI正在经历从"辅助工具"到"协作伙伴"的转变。当智能体能规划、记忆、动手、反思时,人类的角色将从"执行者"升级为"指导者"——设定目标、提供反馈、把控方向。这种转变不仅提升效率,更将释放人类的创造力。
思考问题:当AI智能体能够自主完成80%的知识工作时,哪些人类能力会变得更有价值?是创造力、同理心,还是伦理判断?答案或许就在你构建第一个智能体的过程中。
无论你是开发者、产品经理还是普通用户理解Agentic AI的原理和构建方法,都将是未来十年的关键竞争力。现在就动手实践——用代码赋予AI"思考"和"行动"的能力,参与这场人机协作的新革命。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)