嵌入式开发学习:指针、堆、栈
程序内存空间分为栈(Stack)和堆(Heap)两大区域。
第一部分:内存的宏观蓝图
1、总体概述
要理解堆和栈,首先要明白一个程序在运行时,操作系统会为它分配一个独立的 虚拟地址空间 (Virtual Address Space)。这个空间是程序视角下的内存,它看起来是连续且私有的。这个空间通常被划分为几个主要区域:
-
文本段 (.text): 存放编译后的机器码,这部分是只读的,防止程序意外修改自身指令。
-
数据段 (.data / .bss): 存放全局变量和静态变量。已初始化的放在
.data,未初始化的放在.bss。 -
堆 (Heap): 内存区域,用于动态内存分配。它从低地址向高地址增长。
-
栈 (Stack): 内存区域,用于函数调用。它从高地址向低地址增长。
底层关键点: 堆和栈相对增长的设计是一个经典的内存布局策略。它们从地址空间的两端开始,相向而生,使得两块区域可以最大限度地利用中间的空闲内存,直到它们相遇,内存才算真正耗尽。
2、关于VMP等加密加壳
①概述:
一个未受保护的程序,它在硬盘上的结构(.text, .data段)和加载到内存后的结构基本是一一对应的。而加壳或保护过的程序,其硬盘上的文件更像一个 加密的、自解压的压缩包。它包含三个关键部分:
-
外壳/加载器 (Shell/Loader/Stub): 这是程序的 新入口点。当你双击程序时,操作系统首先执行的是这段代码,而不是你原来的
main函数。 -
被加密/压缩的数据块: 这里面躺着你原来程序的代码(.text)和数据(.data),但它们已经被加密、压缩或完全变形,静态分析工具(如IDA Pro)无法直接识别。
-
原始信息: 可能包含一些用于解密和恢复程序的元数据。
“被安全软件打乱了数据结构的程序为什么还能正常运行工作呢?”
答案是:因为它在运行的瞬间,由其自带的“加载器”在内存中将自己“恢复”成了正确的、可执行的形态。 这个恢复过程对用户和操作系统是透明的。逆向工程师看到的静态文件是混乱的,但CPU在执行前看到的代码和数据是正确的。
保护手段的层级与演进
保护技术不是单一的,而是一个不断升级的军备竞赛。我们可以把它分为几个层级:
②常见的不同加密方式
第一层:压缩壳 (Compressing Packers) - 隐身入门
-
代表工具: UPX (the Ultimate Packer for eXecutables)
-
工作原理:
-
将原始程序的主要区段(.text, .data等)进行压缩(如使用UCL算法)。
-
用一个很小的解压“加载器”替换掉程序的入口点。
-
运行时,加载器在内存中申请一块空间,将压缩的数据解压到这块空间里,恢复成原始程序的样子。
-
最后,通过一个
JMP或CALL指令,将执行权交给恢复后的 原始入口点 (Original Entry Point, OEP)。
-
-
保护作用:
-
缩小体积: 这是它的主要目的。
-
对抗静态特征码: 杀毒软件基于文件特征码的查杀会失效,因为文件内容已经变了。
-
增加静态分析难度: 直接用IDA Pro打开,看到的是解压代码,而不是程序真正的逻辑。不过,对于有经验的逆向者来说,“脱壳”非常容易,只要找到OEP即可。
-
第二层:加密壳与混淆 (Encrypting Packers & Obfuscation) - 高级伪装
在压缩的基础上,这一层引入了更强的安全措施。
-
加密 (Encryption):
-
代替简单的压缩,使用加密算法(如AES, RC4)来保护程序的核心代码和数据。解密的密钥被隐藏在加载器中,或者在运行时动态计算出来。这使得没有密钥,任何人都无法静态地还原出原始代码。
-
-
代码混淆 (Code Obfuscation):
-
这是为了对抗 动态分析(调试)。即使攻击者在内存中dump出了解密后的代码,混淆也会让他们难以理解。
-
花指令 (Junk Code): 插入大量永远不会被执行,但看起来很正常的垃圾指令,干扰逆向者的逻辑判断。
-
指令替换: 将简单的指令替换为功能相同但更复杂、更晦涩的指令序列。例如,
MOV EAX, 0可以被替换为XOR EAX, EAX,或者更复杂的PUSH 0; POP EAX。 -
控制流平坦化 (Control Flow Flattening): 将原本层次分明的
if-else或switch-case结构,变成一个巨大的while循环和一个状态变量。每次循环都根据状态变量goto到真正的代码块,执行完后再更新状态变量。这会把程序的逻辑图变成一团乱麻。
-
-
反调试 (Anti-Debugging):
-
加载器会想尽办法检测自己是否正在被调试器(如x64dbg, OllyDbg)附加。
-
API检测: 调用
IsDebuggerPresent()等Windows API。 -
时钟检测: 通过检测代码执行的时间差。调试时单步执行会让时间差异常巨大。
-
异常处理: 故意触发异常,因为调试器处理异常的方式和正常执行不同。
-
第三层:虚拟机保护 (Virtual Machine Protection) - 终极变形
这是目前最顶级的保护技术,VMP (VMProtect) 就是其中的佼佼者。
-
核心思想: 它不再是简单地“隐藏”原始代码,而是将你的原始代码 “编译”成另一种完全不同的、自定义的“字节码 (Bytecode)”。
-
工作原理:
-
虚拟化 (Virtualization): VMP会扫描你程序的x86汇编代码(例如
ADD EAX, EBX)。 -
编译为字节码: 它会将这条指令转换成它自己定义的字节码。比如,
ADD操作可能被转换成字节码0x01。所以ADD EAX, EBX就变成了类似0x01, REG_EAX, REG_EBX的自定义数据。 -
嵌入虚拟机 (VM): VMP会在你的程序里嵌入一个 虚拟机解释器 (VM Interpreter)。这个解释器就是一段用来理解和执行上述自定义字节码的代码。
-
处理器 (Handlers): 解释器内部有针对每一种字节码的 处理器 (Handler)。例如,当解释器读到字节码
0x01时,它会跳转到ADD操作的Handler,这个Handler内部才是一段执行加法操作的真实x86代码。
-
-
为什么能正常运行?
-
程序运行时,执行权交给了这个虚拟机。
-
虚拟机像一个CPU一样,一条一条地取自定义字节码,然后分发给对应的Handler去执行。
-
最终,通过模拟执行这些字节码,实现了和原始x86代码完全一样的功能。
-
-
为什么保护性极强?
-
逆向工程师面对的不再是熟悉的x86汇编,而是一套闻所未闻的、私有的、没有文档的指令集。
-
他们必须先 完整地逆向整个虚拟机解释器,搞清楚每一种字节码的含义,然后才能开始分析程序的真正逻辑。这个工作量是指数级增长的。
-
更可怕的是,VMP每次编译生成的虚拟机和字节码指令集都是 随机变化 的(这叫Mutation),这意味着逆向A程序的经验无法直接用于逆向B程序。
-
第二部分:栈 (The Stack) - 自动的管家
1、概述
栈是一个由编译器和CPU直接管理的内存区域,它遵循 后进先出 (LIFO, Last-In, First-Out) 的原则。
底层工作原理
-
CPU与栈指针: CPU中有一个特殊的寄存器,通常叫做 栈指针 (Stack Pointer,
ESPon x86,RSPon x86-64)。它始终指向栈顶。 -
函数调用 (Push): 当你调用一个函数时,会发生以下操作:
-
参数入栈: 函数的参数被压入(push)栈中。
-
返回地址入栈: 调用指令的下一条指令的地址被压入栈中,这样函数执行完毕后就知道从哪里继续执行。
-
创建栈帧: 为函数内部的局部变量分配空间。这个操作本质上就是将栈指针
ESP/RSP向下移动(因为栈是向低地址增长的)一段距离,这段被“圈”出来的空间就是该函数的 栈帧 (Stack Frame)。
-
-
函数返回 (Pop): 当函数执行完毕时:
-
销毁栈帧: 将栈指针
ESP/RSP移回原来的位置,释放局部变量所占空间。 -
弹出返回地址: 从栈中取出返回地址,CPU跳转到该地址继续执行。
-
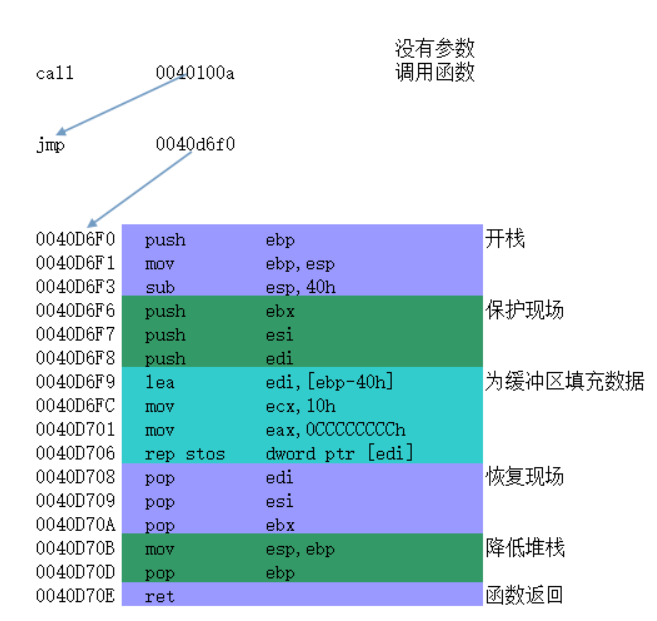
2、图标示例
3、JCC指令补充
补充:JCC指令总结:
JMP指令:修改EIP的值
MOV EIP,寄存器/立即数 简写为 JMP 寄存器/立即数
CALL指令:
PUSH 地址B
MOV EIP,地址A/寄存器 简写为:CALL 地址A/寄存器
RET指令:
LEA ESP,[ESP+4]
MOV EIP,[ESP-4] 简写为:RET
CMP指令:
指令格式:CMP R/M,R/M/IMM
该指令是比较两个操作数,实际上,它相当于SUB指令,但是相减的结构并不保存到第一个操作数中。
只是根据相减的结果来改变零标志位的,当两个操作数相等的时候,零标志位置1。
MOV EAX,100
MOV ECX,100
CMP EAX,ECX 观察Z位
MOV EAX,100
MOV ECX,200
CMP EAX,ECX 观察S位
CMP AX,WORD PTR DS:[405000]
CMP AL,BYTE PTR DS:[405000]
CMP EAX,DWORD PTR DS:[405000]
TEST指令:
指令格式:TEST R/M,R/M/IMM
该指令在一定程序上和CMP指令时类似的,两个数值进行与操作,结果不保存,但是会改变相应标志位.
与的操作表项如下:
1 and 1 = 1
1 and 0 = 0
0 and 1 = 0
0 and 0 = 0
常见用法:用这个指令,可以确定某寄存器是否等于0。
TEST EAX,EAX 观察Z位
但是如果EAX的二进制某些位为1的话,那么运算的结果就不为零。
JJC指令大全:
|
1、 |
JE, JZ |
结果为零则跳转(相等时跳转) |
ZF=1 |
|
2、 |
JNE, JNZ |
结果不为零则跳转(不相等时跳转) |
ZF=0 |
|
3、 |
JS |
结果为负则跳转 |
SF=1 |
|
4、 |
JNS |
结果为非负则跳转 |
SF=0 |
|
5、 |
JP, JPE |
结果中1的个数为偶数则跳转 |
PF=1 |
|
6、 |
JNP, JPO |
结果中1的个数为偶数则跳转 |
PF=0 |
|
7、 |
JO |
结果溢出了则跳转 |
OF=1 |
|
8、 |
JNO |
结果没有溢出则跳转 |
OF=0 |
|
9、 |
JB, JNAE |
小于则跳转 (无符号数) |
CF=1 |
|
10、 |
JNB, JAE |
大于等于则跳转 (无符号数) |
CF=0 |
|
11、 |
JBE, JNA |
小于等于则跳转 (无符号数) |
CF=1 or ZF=1 |
|
12、 |
JNBE, JA |
大于则跳转(无符号数) |
CF=0 and ZF=0 |
|
13、 |
JL, JNGE |
小于则跳转 (有符号数) |
SF≠ OF |
|
14、 |
JNL, JGE |
大于等于则跳转 (有符号数) |
SF=OF |
|
15、 |
JLE, JNG |
小于等于则跳转 (有符号数) |
ZF=1 or SF≠ OF |
|
16、 |
JNLE, JG |
大于则跳转(有符号数) |
ZF=0 and SF=OF |
4、特点总结
-
自动管理: 栈上的内存分配和释放是自动的,由编译器在编译时生成指令完成,无需程序员干预。
-
极高效率: 内存的分配和释放仅仅是移动一下栈指针寄存器,这个操作速度极快。
-
大小限制: 栈的大小在程序启动时通常是固定的(例如在Linux上默认可能是8MB)。如果函数调用嵌套太深,或者局部变量(尤其是数组)过大,会导致栈空间耗尽,引发著名的 栈溢出 (Stack Overflow) 错误。
void myFunction() {
int localVar = 10; // 'localVar' 在 myFunction 的栈帧上分配。
// 当函数返回时,这个空间被自动释放。
}
int main() {
int mainVar = 20; // 'mainVar' 在 main 函数的栈帧上分配。
myFunction();
return 0;
}在上面的例子中,调用myFunction时,内存栈的变化就像这样:
-
main的栈帧 (包含mainVar) -
myFunction的参数 (无) -
返回地址
-
myFunction的栈帧 (包含localVar) <-- 栈顶 当myFunction返回后,2、3、4部分全部被弹出,栈顶回到main的栈帧。
第三部分:堆 (The Heap) - 手动的仓库
1、概述
堆是为 动态内存分配 (Dynamic Memory Allocation) 设计的。当你的程序需要在运行时才能确定需要多少内存,或者需要一个生命周期不随函数调用结束而终结的变量时,就需要在堆上申请内存。
-
C库与操作系统: 堆内存的管理不是由CPU直接控制的,而是由C标准库中的 内存管理器 (Heap Manager) 负责。
malloc,realloc,free就是你与这个管理器交互的接口。 -
内存块链表: 堆管理器内部通常会维护一个数据结构,比如一个空闲内存块的链表 (Free List)。它记录了堆上哪些区域是空闲的,哪些已被占用。
-
malloc(size)的旅程:-
请求: 你的程序调用
malloc,请求一块size大小的内存。 -
查找: 堆管理器在它的空闲链表中查找一个足够大的内存块。查找策略有多种,如首次适应 (First-Fit)、最佳适应 (Best-Fit) 等。
-
分割/分配: 找到后,如果这个块比请求的大,管理器可能会将其分割成两块:一块是程序需要的
size大小(标记为“已占用”),另一块是剩余的(放回空闲链表)。 -
系统调用: 如果空闲链表中没有足够大的块,堆管理器会通过操作系统调用(如Linux下的
brk或mmap)向操作系统申请更多的内存,扩大堆的边界,然后再进行分配。 -
返回:
malloc返回这块已分配内存的起始地址。如果系统内存耗尽,则返回NULL。
-
2、特点总结
-
手动管理: 程序员必须显式地通过
malloc(或calloc) 申请内存,并通过free释放。忘记free会导致 内存泄漏 (Memory Leak)。 -
相对低效:
malloc的过程涉及查找、分割、记录等复杂操作,可能还需要昂贵的系统调用,因此比栈上的分配慢得多。 -
空间巨大: 堆的大小受限于可用的虚拟地址空间和物理内存,通常非常大。
-
内存碎片: 由于频繁地分配和释放大小不一的内存块,堆上可能会出现许多不连续的小空闲块。这被称为 内存碎片 (Memory Fragmentation)。即使总的空闲空间足够,也可能因为没有一个连续的大块而导致
malloc失败。
3、演示
①场景一:基本且正确的堆内存使用 (malloc 和 free)
这是最基础的“申请-使用-释放”模式,是所有堆操作的基石。
#include <stdio.h>
#include <stdlib.h> // 包含 malloc, free
int main() {
int* dynamicArray = NULL;
int size = 5;
// 1. 在堆上申请内存
// sizeof(int) 保证了跨平台兼容性(int可能不是4字节)
// (int*) 是类型转换,因为 malloc 返回 void*
dynamicArray = (int*)malloc(size * sizeof(int));
// 2. 检查内存分配是否成功
// 这是一个至关重要的好习惯!
if (dynamicArray == NULL) {
fprintf(stderr, "内存分配失败!\n");
return 1; // 返回错误码
}
printf("内存分配成功,地址为:%p\n", (void*)dynamicArray);
// 3. 像普通数组一样使用这块内存
for (int i = 0; i < size; i++) {
dynamicArray[i] = i * 10;
printf("dynamicArray[%d] = %d\n", i, dynamicArray[i]);
}
// 4. 使用完毕,必须手动释放
free(dynamicArray);
printf("内存已释放。\n");
// 良好实践:将指针设置为 NULL,防止悬挂指针
dynamicArray = NULL;
return 0;
}内存分配成功,地址为:0x14b52a0
dynamicArray[0] = 0
dynamicArray[1] = 10
dynamicArray[2] = 20
dynamicArray[3] = 30
dynamicArray[4] = 40
内存已释放。
解析:
-
malloc(size * sizeof(int)):程序向C标准库的堆管理器请求20字节(假设sizeof(int)为4)的连续空间。 -
堆管理器在内部的空闲链表中找到一个足够大的块,将其标记为“已占用”,并返回该块的起始地址。
-
dynamicArray这个指针变量本身存储在main函数的 栈 上,但它指向的值(20字节的连续空间)位于 堆 上。 -
free(dynamicArray):程序将这块内存的控制权交还给堆管理器。管理器会将其标记为“空闲”,并可能与相邻的空闲块合并。此时,这块内存可以被后续的malloc调用再次分配。
②场景二:内存泄漏 (Memory Leak) - 忘记 free
这是最常见的堆内存错误。
#include <stdio.h>
#include <stdlib.h>
void create_leak() {
int* leakyPointer = (int*)malloc(10 * sizeof(int));
if (leakyPointer == NULL) return;
printf("在函数内部,分配了内存于地址:%p\n", (void*)leakyPointer);
// ... 做了一些工作 ...
// 函数结束,但没有调用 free()
} // <-- leakyPointer (栈上的指针变量) 在此被销毁
int main() {
printf("调用 create_leak() 函数...\n");
create_leak();
printf("函数已返回。\n");
// 在这里,我们已经永远失去了对那块分配的内存的引用。
// 它无法被访问,也无法被释放。
return 0;
}解析:
-
create_leak函数内,leakyPointer在 栈 上被创建。 -
malloc在 堆 上分配了40字节内存,并将其地址赋给了leakyPointer。 -
函数
create_leak执行结束,其栈帧被销毁。这意味着leakyPointer这个指针变量本身不复存在了。 -
核心问题: 指针变量
leakyPointer消失了,我们失去了访问那40字节堆内存的唯一途径。但对于堆管理器来说,那块内存仍然是“已占用”状态。 -
这个程序虽然能正常结束,但在它运行期间,这40字节的内存被无效地占用了。如果这种情况在循环或长时间运行的程序中反复发生,会逐渐耗尽系统可用内存,导致程序性能下降甚至崩溃。
③场景三:悬挂指针 (Dangling Pointer) - free 后继续使用
这是一个极其危险的错误,其行为是未定义的,可能导致程序立即崩溃,也可能在未来的某个时刻以诡异的方式崩溃或产生错误数据。
#include <stdio.h>
#include <stdlib.h>
int main() {
int* danglingPointer = (int*)malloc(sizeof(int));
if (danglingPointer == NULL) return 1;
*danglingPointer = 123;
printf("释放前:地址 %p, 值 %d\n", (void*)danglingPointer, *danglingPointer);
// 释放内存
free(danglingPointer);
printf("内存已释放。指针 danglingPointer 仍指向地址 %p\n", (void*)danglingPointer);
// ----------------- 危险操作!-----------------
// 此时 danglingPointer 成为了一个悬挂指针。
// 它指向的内存已经不属于我们了。
// 后续行为完全不可预测。
// 尝试写入
printf("尝试向悬挂指针写入数据...\n");
*danglingPointer = 456; // 未定义行为 (Undefined Behavior)
// 尝试读取
printf("尝试读取悬挂指针的值:%d\n", *danglingPointer); // 未定义行为
// 更有可能的情况:
int* anotherPointer = (int*)malloc(sizeof(int));
printf("另一个指针被分配到地址:%p\n", (void*)anotherPointer);
// 堆管理器很可能会重用刚刚被 free 的内存
// 如果 anotherPointer 和 danglingPointer 指向同一地址...
*anotherPointer = 789;
// 这时你以为在读一个已经被释放的变量,实际上读的是另一个变量的值!
printf("再次读取悬挂指针的值:%d\n", *danglingPointer);
free(anotherPointer);
return 0;
}可能的输出 (非常不确定, 每次运行都可能不同!)
释放前:地址 0x1d3e4a0, 值 123
内存已释放。指针 danglingPointer 仍指向地址 0x1d3e4a0
尝试向悬挂指针写入数据...
尝试读取悬挂指针的值:456
另一个指针被分配到地址:0x1d3e4a0
再次读取悬挂指针的值:789
解析:
-
free(danglingPointer)通知堆管理器:“地址0x1d3e4a0处的内存现在空闲了。” -
关键点:
free函数 不会 改变danglingPointer变量本身的值。它里面存储的地址0x1d3e4a0保持不变。 -
此时,
danglingPointer就成了悬挂指针。它像一个房产中介,手里还拿着一个房子的钥匙,但这个房子已经被卖给了别人。 -
当你通过它写入数据 (
*danglingPointer = 456),你可能正在破坏堆管理器的内部数据结构(通常紧邻分配块存放),或者正在破坏另一个完全无关的变量(如果这块内存已被malloc重新分配)。这就是为什么程序的行为变得不可预测。 -
最佳实践:
free(ptr); ptr = NULL;。NULL是一个安全的、定义明确的“不指向任何地方”的地址,对NULL指针解引用通常会立即导致程序崩溃,这反而能帮助你快速定位错误,而不是让它变成一个潜伏的、难以追踪的bug。
④场景四:realloc 的使用与陷阱
realloc 用于调整已分配内存的大小,但它的行为需要特别注意。
#include <stdio.h>
#include <stdlib.h>
int main() {
// ---- Part 1: realloc 成功 ----
int* ptr = (int*)malloc(3 * sizeof(int));
if (ptr == NULL) return 1;
printf("初始地址: %p\n", (void*)ptr);
// 尝试扩大内存。地址可能会变,也可能不变。
int* new_ptr = (int*)realloc(ptr, 10 * sizeof(int));
// 必须检查 realloc 的返回值!
if (new_ptr == NULL) {
// 如果 realloc 失败,原指针 ptr 仍然有效,需要我们手动释放
fprintf(stderr, "realloc 失败!\n");
free(ptr);
return 1;
}
// 只有在成功后,才更新我们的主指针
ptr = new_ptr;
printf("realloc 后的地址: %p\n", (void*)ptr);
// 现在可以安全地使用更大的空间了
ptr[9] = 99;
printf("ptr[9] = %d\n", ptr[9]);
free(ptr);
ptr = NULL;
return 0;
}初始地址: 0x22a0ab0
realloc 后的地址: 0x22a0b10
ptr[9] = 99
解析:
-
realloc首先会检查原内存块(ptr指向的)后面是否有足够的连续空闲空间。-
如果有: 它会直接扩展这块内存的边界,并返回 相同的地址。
-
如果没有(如输出所示): 它会在堆的其他地方找到一个足够大的新空间,将旧空间的数据 拷贝 到新空间,然后 释放 旧空间,最后返回 新空间的地址。
-
-
最大的陷阱(安全模式): 如果
realloc失败(比如内存不足),它会返回NULL,并且 不会释放 原来的内存块。如果你直接写ptr = realloc(ptr, ...),一旦失败,ptr会被NULL覆盖,你就丢失了对原始内存块的唯一引用,造成了内存泄漏。因此,必须使用一个临时指针(如new_ptr)来接收realloc的返回值。
⑤场景五:更安全、更干净的内存分配 (calloc)
calloc (contiguous allocation) 函数与 malloc 非常相似,都用于在堆上分配内存,但有两个关键区别:
-
参数不同: 它接收两个参数:元素的数量和每个元素的大小。
-
自动初始化: 它会自动将分配的所有内存位(bits)初始化为零。
#include <stdio.h>
#include <stdlib.h> // 包含 calloc, malloc, free
int main() {
int num_elements = 5;
// ---- Part 1: 使用 calloc 分配内存 ----
int* callocArray = NULL;
callocArray = (int*)calloc(num_elements, sizeof(int));
if (callocArray == NULL) {
fprintf(stderr, "calloc 内存分配失败!\n");
return 1;
}
printf("calloc 分配成功,地址为:%p\n", (void*)callocArray);
printf("检查 calloc 分配后的初始内容:\n");
// 我们没有对数组进行任何赋值操作,直接打印内容
for (int i = 0; i < num_elements; i++) {
printf("callocArray[%d] = %d\n", i, callocArray[i]);
}
printf("\n");
// ---- Part 2: 使用 malloc 分配内存作为对比 ----
int* mallocArray = NULL;
mallocArray = (int*)malloc(num_elements * sizeof(int));
if (mallocArray == NULL) {
fprintf(stderr, "malloc 内存分配失败!\n");
free(callocArray); // 记得释放之前分配的内存
return 1;
}
printf("malloc 分配成功,地址为:%p\n", (void*)mallocArray);
printf("检查 malloc 分配后的初始内容:\n");
// 同样,不进行任何赋值,直接打印
for (int i = 0; i < num_elements; i++) {
// 这些值是之前这块内存遗留下来的“垃圾数据”
printf("mallocArray[%d] = %d\n", i, mallocArray[i]);
}
printf("\n");
// ---- Part 3: 清理 ----
free(callocArray);
free(mallocArray);
printf("内存已全部释放。\n");
return 0;
}calloc 分配成功,地址为:0x18b16b0
检查 calloc 分配后的初始内容:
callocArray[0] = 0
callocArray[1] = 0
callocArray[2] = 0
callocArray[3] = 0
callocArray[4] = 0
malloc 分配成功,地址为:0x18b16f0
检查 malloc 分配后的初始内容: mallocArray[0] = 0 // <-- 这些值是完全不可预测的
mallocArray[1] = 135432 // <-- 可能是任何随机数
mallocArray[2] = -582190 //
mallocArray[3] = 21934 //
mallocArray[4] = 1 //
内存已全部释放。
(注意: mallocArray 的初始值在每次运行时都可能不同)
解析:
calloc 与 malloc 的差异,从底层来看主要体现在三个方面:
-
参数与整数溢出安全 (Integer Overflow Safety):
-
malloc(num_elements * sizeof(int)):这里的乘法是由你的代码在调用malloc之前 计算的。如果num_elements和sizeof(int)的乘积非常大,超出了size_t类型的最大值,就会发生 整数溢出。例如,一个巨大的乘法结果可能溢出并变成一个很小的正数。malloc会成功分配这个小块内存,但你的程序会以为得到了一块巨大的内存,后续的写入操作将导致灾难性的 缓冲区溢出。 -
calloc(num_elements, sizeof(int)):乘法是在calloc函数内部完成的。calloc的实现会检查这个乘法是否会导致溢出。如果会,它将直接返回NULL,从而避免了上述安全漏洞。因此,在分配元素数组时,calloc本质上比malloc更安全。
-
-
内存初始化 (Memory Initialization):
-
malloc:仅仅是“圈地”。它在堆上找到一块空闲内存并返回给你,但它 不会 对这块地进行任何清理。里面可能包含之前使用者留下的任何数据,甚至是密码、密钥等敏感信息的残留。直接使用未经初始化的malloc内存是导致程序逻辑错误和安全漏洞的常见原因。 -
calloc:是“圈地并清扫”。在返回内存地址之前,它会负责将这块内存的每一个字节都设置为0。这相当于在内部执行了malloc之后紧接着调用memset(ptr, 0, size)。这确保了你拿到的是一块干净、可预测的内存,对于数字类型就是0,对于指针就是NULL,对于字符就是'\0'。
-
-
性能 (Performance):
-
天下没有免费的午餐。由于
calloc多了清零这一步操作,它的速度通常会比malloc略慢。 -
选择依据:
-
追求极致性能,并且你确定马上会手动初始化所有内存(例如,从文件读取数据来填充缓冲区),使用
malloc。 -
追求安全和便利,或者你需要一块保证为零的初始内存(例如,用作计数器数组、构建哈希表等),
calloc是更好的选择。多出的这点开销换来的安全性和代码简洁性通常是值得的。
-
-
总而言之,calloc 提供了一种更稳健的内存分配方式,以微小的性能代价换取了对两大常见编程错误的免疫:整数溢出漏洞和未初始化内存的使用。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)