揭秘-英伟达GPU全系图谱:架构进化史与性能参数深度解析
GDDR打游戏,HBM算大模型,LPDDR跑移动设备** —— 显存类型的选择,本质是**性能、功耗与成本之间的战略权衡**。高端AI芯片为何不惜成本用HBM?因为大模型“吃数据如饮水”,没有高带宽,再强的算力也只能“饿着等”。
引言:
我们熟知的诸多AI“巨兽”级大模型,背后几乎都离不开NVIDIA GPU的强力支撑。
从OpenAI的GPT-4,到DeepSeek系列模型,再到Meta的Llama-4、xAI的Grok-3,这些引领行业风向的顶尖大模型无一例外选择了英伟达的GPU作为训练基石。
正因有这些成功案例树立标杆,NVIDIA GPU俨然成为AI领域的“黄金标准”,吸引着全球科技公司争相追捧,趋之若鹜。

一:“芯”火燎原:NVIDIA GPU 架构从 Fermi 到 Blackwell 的爆裂进化
1.核心性能参数
1.1浮点运算能力(FLOPS):AI算力的“速度标尺”
FLOPS,全称 --Floating-point Operations Per Second--,即每秒可执行的浮点运算次数。它是衡量GPU计算性能最核心的指标之一,相当于显卡的“算术引擎”马力大小。我们常说的“算力有多强”,本质上就是在看它的FLOPS值。
那什么是浮点运算?
简单来说,就是处理带小数点的数字运算,比如:3.14 × 2.71 或者 0.001 ÷ 0.5。相比整数运算,浮点计算更复杂、更灵活,而AI训练、科学模拟、图形渲染等任务,正是这类运算的“重度用户”。
1.2单位换算一览:
- 1 FLOPS = 每秒1次浮点运算
- 1 TFLOPS = 每秒1万亿次(10¹²)浮点运算(主流显卡常用单位)
- 1 PFLOPS = 每秒1000万亿次(10¹⁵)浮点运算(超算级别)
现在的NVIDIA GPU参数表上,动辄标着“300 TFLOPS”、“1000 TFLOPS”,这个数字越大,意味着它在单位时间内能“算得更多、更快”。
1.3FP16、FP32、FP64:精度的“三重境界”
这些术语指的是浮点数在计算机中的存储格式,决定了数值的精度和计算效率:
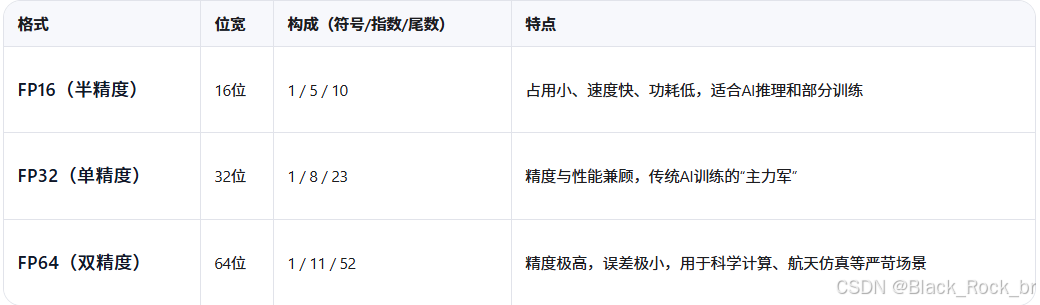
精度越高,代价越大 —— 计算更慢、显存占用更高、功耗也更大。
1.4实际应用怎么选?
- FP16-:AI时代的“效率王者”。如今大多数大模型推理和混合精度训练都依赖它,在速度与精度之间取得极佳平衡,是当前主流选择。
- FP32-:经典“中庸之道”。适合对精度有要求但又不想牺牲太多性能的场景,常用于传统训练流程。
- FP64-:追求极致精度的“科学家之选”。比如模拟宇宙演化、计算火箭轨道,差之毫厘,谬以千里,非它不可。
1.5趋势:
过去大模型训练以FP32为主流,如今**混合精度训练**(FP32 + FP16结合)已成为标配,既保证了训练稳定性,又大幅提升了速度和能效。而在推理端,FP16甚至更低精度(如INT8、FP8)正加速普及,推动AI落地更轻、更快、更省。
所以,当你看到某款GPU标称“FP16算力高达1000 TFLOPS”,那它很可能就是为AI而生的“算力猛兽”。
2.芯脉 · 架构编年史
—— 每一代 NVIDIA GPU 都刻着一位科学巨匠的名字
在 GPU 世界里,架构就是灵魂。两张显卡若架构不同,就算 CUDA 数、显存、频率完全一致,跑出来的帧率和算力也可能天差地别。NVIDIA 的架构迭代像是科技界的“年轮”,每几年便迎来一次大换血:越晚登场,越凶猛。
时间轴一览(按首次发布时间排序)
• Tesla(2006)—— 点燃通用计算的火种
• Fermi(2010)—— 首款完整 L2 Cache 设计,奠定现代 GPU 框架
• Kepler(2012)—— 双倍能效比,游戏与超算双开花
• Maxwell(2014)—— 能耗大师,让笔记本也能塞进旗舰芯
• Pascal(2016)—— 16 nm FinFET 首航,VR & 深度学习起飞
• Volta(2017)—— Tensor Core 首秀,AI 训练进入核弹级时代
• Turing(2018)—— RT Core 降临,实时光追照进现实
• Ampere(2020)—— 7 nm 大跃进,FP32/INT32 并发翻倍
• Hopper(2022)—— H100 登顶 AI 算力王座,H20 特供版紧随其后
• Ada Lovelace(2022)—— RTX 40 系列,着色器频率直冲 3 GHz+
• Blackwell(2024)—— B200 剑指下一代 AI 超算,功耗与晶体管一起爆炸
一句话总结:买 GPU 不仅要看 CUDA、显存,还得先认清它是哪位“科学家”的弟子。
3.流处理器(CUDA核心)
CUDA核心:NVIDIA GPU的“并行计算细胞”
CUDA,全称 --Compute Unified Device Architecture--,而其中的 CUDA核心 ,是NVIDIA GPU中最基础的计算单元,堪称GPU的“算力基石”。
你可以把一个CUDA核心想象成一个擅长执行简单数学运算(比如浮点加法、乘法)的“微型计算器”。单个核心能力有限,但胜在数量惊人——现代高端GPU动辄集成上万个CUDA核心。
正是这种“人海战术”,让GPU具备了远超CPU的--并行处理能力。CPU像是一位全能学霸,擅长串行处理复杂任务;而GPU则像一支由成千上万名工人组成的高效团队,能同时处理海量相似的计算任务,尤其适合AI训练、图像渲染、科学模拟等高并发场景。
简单来说:CUDA核心越多,GPU的并行算力越强,处理大规模数据就越快。
这也正是NVIDIA凭借CUDA生态,在AI和高性能计算领域建立起强大护城河的关键所在——硬件+架构+软件的深度协同,让这些“小核心”爆发出“大能量”。
4.张量核心(Tensor Core)
如果把 CUDA 核心比作“单兵步枪”,那 Tensor Core 就是“连发火箭炮”。
CUDA 一次只扣动一次扳机——发射一个标量;而 Tensor Core 一炮齐射——直接把 4×4 甚至更大块的矩阵打包轰出,爆炸式吞吐。深度学习里动辄百万级矩阵乘,Tensor Core 的“齐射”让它在同样时间里完成 CUDA 需要数百次射击才能搞定的活儿,效率瞬间拉满。
5.Tensor性能(Tensor TFLOPS);AI算力的“加速引擎”
Tensor TFLOPS 是衡量 GPU 或 AI 加速器在执行**张量运算**(Tensor Operations)时的浮点计算能力,是评估其在深度学习训练与推理中实际性能的关键指标。它特指由 NVIDIA **Tensor Core** 所提供的加速算力——这些专用硬件单元专为矩阵乘加运算(如 GEMM)这类深度学习核心操作而设计,能够以极高的效率处理神经网络中的大规模张量计算。
相比传统 CUDA 核心,Tensor Core 可在单个周期内完成一个完整的矩阵运算(例如 4×4 的浮点矩阵乘法),并支持 FP16、BF16、FP8、甚至 INT8 等低精度格式,实现数倍乃至数十倍的性能跃升。因此,Tensor TFLOPS 数值越高,意味着该 GPU 在 AI 任务中的实际加速能力越强。
📌 一个关键洞察:企业采购看“性能”,而非“数量”
在实际选型中,企业决策者通常**不会紧盯 Tensor Core 的具体数量**,因为不同架构(如 Ampere、Hopper、Blackwell)的 Tensor Core 设计不同,跨代比较“个数”毫无意义。
相反,他们更关注的是**实测或标称的 Tensor 性能(即 Tensor TFLOPS)**——这个指标更能真实反映 GPU 在 AI 工作负载下的吞吐能力。毕竟,买的是“算得快”,不是“核心多”。
✅ 所以,Tensor TFLOPS 才是AI基础设施选型中的“硬通货”:数字越大,AI训练越快,推理延迟越低,投资回报越高。
6.Int8 (Int8量化)
二:.显存配置
1.显存容量
显存是 GPU 的“速写板”——游戏帧、3D 网格、AI 张量都会先在上面打草稿。容量不是越大越豪,合适才最香:
• 4K 游戏 8~12 GB 就够浪
• 8K 渲染或百亿参数大模型才需要 24 GB+
而专业怪兽 A100 直接塞满 80 GB HBM2,一口气吞下整头 Transformer,训练不掉链子。
2.显存位宽与带宽
显存位宽与带宽:GPU的“数据高速公路”
如果说GPU是超级大脑,那么显存就是它的短期记忆仓库,而**显存位宽**和**显存带宽**,就是连接大脑与记忆之间的“数据高速公路”。
2.1 显存位宽(Memory Bus Width)
单位是 **bit**(位),常见如 192-bit、256-bit、384-bit 等。它相当于这条高速公路的“车道数量”——位宽越宽,每秒能并行传输的数据就越多。
想象一下:一条8车道的高速比2车道能同时通行更多车辆,GPU也能更高效地从显存中抓取数据,避免“堵车”。
2.2显存带宽(Memory Bandwidth)
单位是 **GB/s**(每秒千兆字节),表示GPU每秒能从显存中读取或写入多少数据。它是“实际通行能力”的体现,取决于两个关键因素:
> **带宽 = 位宽 × 显存频率 ÷ 8**
你可以把带宽理解为“单位时间内的车流量”——即使马路很宽(位宽大),但如果车速慢(显存频率低),整体通行效率依然上不去。
2.3 一个生动类比:
- 位宽 = 马路宽度(车道数)
- 显存频率 = 车辆速度
- 带宽 = 每小时能通过的车辆总数 (通行效率)
因此,高带宽意味着GPU能更快地获取模型参数、特征图等海量数据,尤其在运行大模型训练、高分辨率渲染等数据密集型任务时,带宽直接决定了性能上限。
2.4综合评价:
位宽是基础,带宽是结果。真正影响GPU“不卡顿、不等待”的,是最终的**显存带宽**。高端AI计算卡(如H100、B200)普遍采用HBM3高带宽显存,带宽可达数千GB/s,正是为了满足大模型“吞吐如海”的数据需求。
3.显存类型
显存类型揭秘:GPU的“记忆体质”决定性能边界
显存(VRAM)是GPU的专用内存,负责高速存储和供给图形、模型参数、特征图等关键数据。但你可能不知道——**显存的“类型”**,往往比容量更深刻地影响着GPU的性能上限、能效表现和应用场景。
目前主流的显存技术分为三大类,各有所长,各司其职:
3.1 GDDR(Graphics DDR)—— 游戏与消费级显卡的“主力军”
- **代表型号**:GDDR6、GDDR6X、GDDR7(最新)
- **特点**:高带宽、相对低成本、广泛普及
- **应用场景**:主流游戏显卡(如RTX 40系列)、工作站显卡
GDDR是为图形性能优化而生,凭借出色的性价比,成为消费级GPU的首选。虽然带宽不及HBM,但在大多数游戏和创意设计任务中表现优异。
3.2HBM(High Bandwidth Memory)—— AI与超算的“顶配记忆”
- **代表型号**:HBM2e、HBM3、HBM3e(最新)
- **特点**:超高带宽、低功耗、堆叠式设计、成本高昂
- **应用场景**:数据中心、AI训练芯片(如NVIDIA H100、B200)、超级计算机
HBM采用3D堆叠技术,将显存芯片垂直堆叠在GPU旁边,通过硅中介层(Interposer)连接,极大缩短数据路径,实现**数千GB/s的恐怖带宽**(H100可达3.35 TB/s)。它是大模型训练、高性能计算的“黄金标准”,只为极致性能而生。
3.3 LPDDR(Low Power DDR)—— 移动与边缘设备的“节能专家”
- 常见类型:LPDDR4、LPDDR5、LPDDR5X
- 特点:超低功耗、小体积、中等带宽
- 应用场景:手机、平板、AI边缘设备(如Jetson系列)、轻薄笔记本
LPDDR专为能效优化,虽然带宽和性能不及前两者,但在电池供电的设备中至关重要。它让移动GPU在有限功耗下依然能运行轻量级AI模型和图形任务。
一句话总结:
> GDDR打游戏,HBM算大模型,LPDDR跑移动设备** —— 显存类型的选择,本质是**性能、功耗与成本之间的战略权衡**。
高端AI芯片为何不惜成本用HBM?因为大模型“吃数据如饮水”,没有高带宽,再强的算力也只能“饿着等”。
三:芯战图鉴:NVIDIA GPU 全族谱一键速通
你是否总在AI新闻、技术论坛或服务器配置单里看到这些名字:H100、A100、H20、GeForce RTX……它们被频频提及,仿佛是通往高性能AI世界的“通行证”。但这些GPU到底有何不同?为什么有的用于训练万亿参数大模型,有的却只适合打游戏?
其实,它们分属NVIDIA产品矩阵的不同“战线”,针对的是--截然不同的应用场景、性能需求和预算层级--。选对GPU,就像选对武器——打游戏用核弹是浪费,训大模型用核显则寸步难行。
下面我们从应用出发,带你一文理清NVIDIA主流GPU的“角色定位”与“能力边界”。


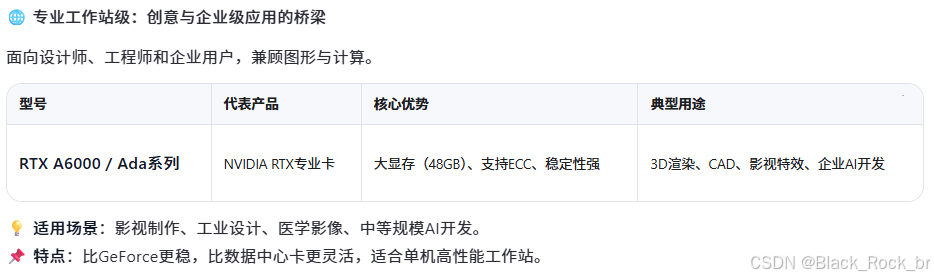
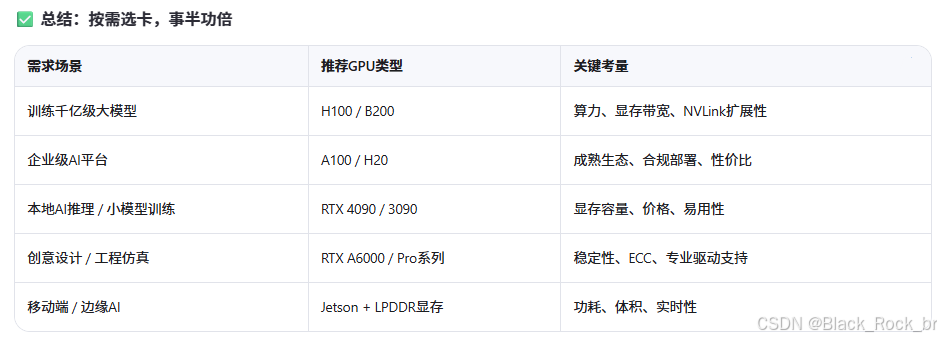
一句话收尾:
H100是“AI时代的核反应堆”,GeForce是“大众玩家的算力玩具”,而A100和H20,则是企业通往智能未来的“关键跳板”。
选哪一款,取决于你要解决的问题——有多大,有多急,有多烧钱
终章 · 芯火未歇
就在本文落笔之际,代号 “Rubin” 的下一代 GPU 架构已揭开面纱——2026 年初,它将以光速走下产线,再次刷新摩尔定律的刻度尺。
从当年让像素跳舞的游戏利器,到如今让模型思考的 AI 引擎,英伟达用一次次“自砍上限”的手术式迭代,把算力天花板亲手打碎,再亲手垒高。
这不是简单的升级,而是一场无限循环的极限跑酷:每一代架构都是上一代的“终结者”,也是下一代的“垫脚石”。
正因如此,行业才甘愿追随它的尾灯,在光追、张量、量子噪声与神经网络的交错光影里狂奔。
无人能并肩?也许只是此刻。
科技的剧本从不缺反转——下一位掀桌者,或许已在暗处蓄能。
让我们拭目以待,看是谁再次点燃芯火,照亮新的黎明。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)